
✒️ 0. 들어가기 전
시간복잡도와 공간복잡도는 알고리즘의 효율성을 측정하는 중요한 개념이다.
시간복잡도는 알고리즘 실행 시간을, 공간복잡도는 필요한 메모리 공간을 나타낸다.
또한 빅오 표기법은 이러한 복잡도를 간단하게 표현하는 방법이다.
자료구조와 알고리즘에서 빠질 수 없는 복잡도(Complexity) ...
단순히 개념적으로만 알아둬야 할 게 아니고, 코딩테스트를 볼 때에도 꼭 알아둬야 할 파트이다.
너무 추상적인 복잡도는 항상 [런타임 에러]로 나를 괴롭혔다..
뿐만 아니라 코딩을 할 때 가장 신경써야 할 "효율" "성능" 개선에 빠질 수 없는 내용이다.
✒️ 1. 복잡도(Complexity)란?
알고리즘의 복잡도는 컴퓨터 과학에서 알고리즘의 성능을 평가하는 중요한 척도이다.
복잡도는 주로 시간 복잡도와 공간 복잡도로 구분된다.
이들은 각각 알고리즘의 실행 시간과 메모리 사용량을 나타낸다.
복잡도 분석은 알고리즘의 효율성을 객관적으로 평가하고 비교할 수 있게 해주는 핵심적인 도구이다.
간단하게 "이 알고리즘이 얼마나 효율적인가!?"
✒️ 2. 시간 복잡도 (Time Complexity)
시간 복잡도는 알고리즘이 문제를 해결하는 데 필요한 연산의 횟수를 의미한다.
이는 입력 크기에 따른 알고리즘의 실행 시간 증가율을 나타내며,
알고리즘의 효율성을 평가하는 가장 중요한 지표 중 하나이다.
시간 복잡도를 분석할 때는 주로 최악의 경우(worst-case)를 고려한다.
이는 알고리즘이 가장 오래 걸리는 경우를 대비하기 위함이다.
예를 들어, n개의 요소를 가진 배열에서 특정 요소를 찾는 선형 검색 알고리즘의 시간 복잡도는 O(n)이다.
최악의 경우, 찾고자 하는 요소가 배열의 마지막에 있거나 배열에 없을 때 n번의 비교 연산이 필요하기 때문이다.
반면, 정렬된 배열에서 이진 검색을 수행하는 경우, 시간 복잡도는 O(log n)이 된다.
이는 매 단계마다 검색 범위를 절반으로 줄이기 때문에, 입력 크기가 두 배로 증가할 때마다 필요한 연산의 수는 단 1회만 증가한다.
✒️ 3. 공간 복잡도 (Space Complexity)
공간 복잡도는 알고리즘이 실행되는 동안 사용하는 메모리의 양을 나타낸다.
이는 입력 데이터를 저장하는 데 필요한 고정 공간과 알고리즘이 실행되면서 추가로 사용하는 가변 공간으로 구성된다.
예를 들어, n개의 정수를 입력받아 그 합을 계산하는 간단한 알고리즘의 공간 복잡도는 O(1)이다.
입력의 크기에 관계없이 합을 저장할 변수 하나만 필요하기 때문이다.
반면, n x n 행렬의 곱셈을 계산하는 알고리즘의 공간 복잡도는 O(n^2)이다.
결과를 저장할 n x n 크기의 새로운 행렬이 필요하기 때문이다.
💡 시간 복잡도와 공간 복잡도의 관계
시간 복잡도와 공간 복잡도는 반비례하는 경향이 있다. (Trade-Off)
시간을 절약하기 위해 더 많은 공간을 사용하거나, 반대로 공간을 절약하기 위해 더 많은 시간을 소비하는 경우가 많다.
또한, 최근에는 메모리 비용이 상대적으로 저렴해져 시간 복잡도에 비해 공간 복잡도의 중요성이 다소 낮아졌다.
그러나 대용량 데이터를 다루는 빅데이터 분야나 제한된 자원을 가진 임베디드 시스템에서는 여전히 공간 복잡도가 중요한 고려 사항이다.
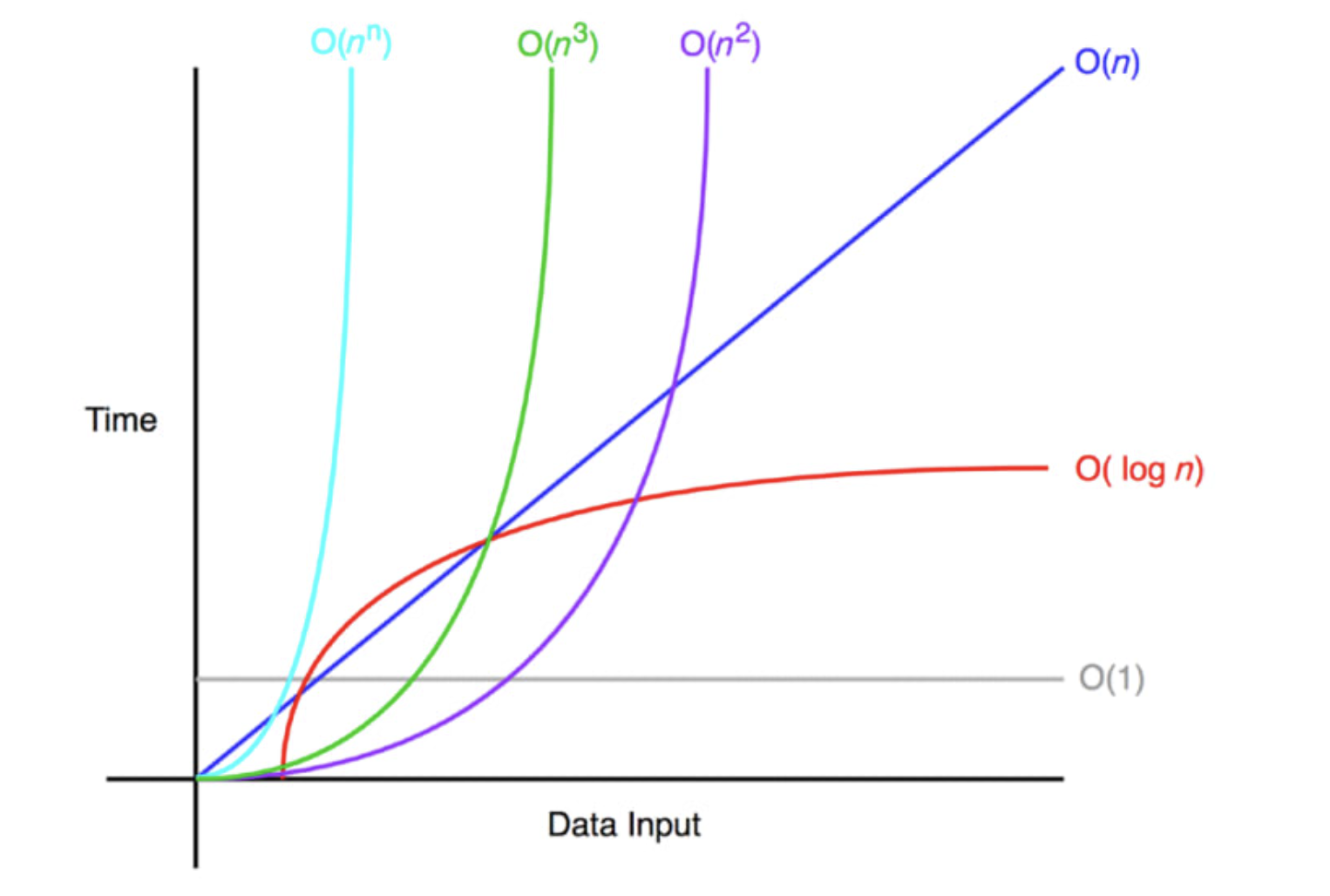
✒️ 4. 빅오 표기법 (Big-O Notation)
빅오 표기법은 알고리즘의 복잡도를 간단하고 일반화된 형태로 표현하는 방법이다.
이 표기법은 입력 크기가 무한히 커질 때 알고리즘의 성능을 나타내며, 가장 빠르게 증가하는 항만을 고려한다.
빅오 표기법의 주요 특징은 다음과 같다:
1. 상수항 무시: O(2n)은 O(n)으로 표기한다.
2. 계수 무시: O(3n^2)도 O(n^2)로 표기한다.
3. 낮은 차수 무시: O(n^2 + n)은 O(n^2)로 표기한다.
이러한 특징들로 인해 빅오 표기법은 알고리즘의 효율성을 대략적으로 비교하는 데 매우 유용하다.
✒️ 5. 시간 복잡도 & 빅오 표기법
시간 복잡도는 특정 크기의 입력(n)을 기준으로 실행하는 연산의 횟수.
-> 핵심이 되는 연산의 횟수만 세면 된다.
물론 코드를 보고 시간 복잡도를 구하는 문제도 [자료구조] 수업에서 많이 풀었었는데,
예제를 다루지는 않겠다.
| 복잡도 | 소요 시간 | 예시 |
|---|---|---|
| O(1) | 상수 시간 | - 스택에서 Push, Pop - 배열의 인덱스 접근 - 해시 테이블의 삽입/조회 (평균 경우) => dictionary 등 사용 권장 |
| O(log n) | 로그 시간 | - 이진 검색 - 균형 이진 트리의 검색/삽입/삭제 - 힙(Heap)의 삽입/삭제 => heapq 사용 권장 |
| O(n) | 선형 시간 | - 단일 for 문 - 선형 검색 - 단일 연결 리스트의 순회 |
| O(n log n) | 선형 로그 시간 | - 퀵 정렬(평균 경우) - 병합 정렬 - 힙 정렬 - 효율적인 비교 기반 정렬 알고리즘 |
| O(n^2) | 2차 시간 | - 이중 for 문 (중첩 for 문의 개수에 따라 n의 x제곱이 된다.) - 버블 정렬 - 선택 정렬 - 삽입 정렬 |
| O(2^n) | 지수 시간 | - 부분 집합 생성 - 피보나치 수열(재귀 구현) - 외판원 문제(브루트 포스) |
| O(n!) | 팩토리얼 시간 | - 순열 생성 - 여행 경로 문제(모든 경우의 수) |
💡 자료구조별 시간 복잡도
| 자료구조 | 검색 (평균) | 삽입 (평균) | 삭제 (평균) | 검색 (최악) | 삽입 (최악) | 삭제 (최악) |
|---|---|---|---|---|---|---|
| 배열 | O(n) | N/A | N/A | O(n) | N/A | N/A |
| 정렬된 배열 | O(log n) | O(n) | O(n) | O(log n) | O(n) | O(n) |
| 연결 리스트 | O(n) | O(1) | O(1) | O(n) | O(1) | O(1) |
| 이중 연결 리스트 | O(n) | O(1) | O(1) | O(n) | O(1) | O(1) |
| 스택 | O(n) | O(1) | O(1) | O(n) | O(1) | O(1) |
| 해시 테이블 | O(1) | O(1) | O(1) | O(n) | O(n) | O(n) |
| 이진 검색 트리 | O(log n) | O(log n) | O(log n) | O(n) | O(n) | O(n) |
| B-Tree Red-Black Tree AVL Tree |
O(log n) | O(log n) | O(log n) | O(log n) | O(log n) | O(log n) |
💡 정렬 알고리즘별 복잡도
| 정렬 알고리즘 | 공간 복잡도 | 시간 복잡도 (최선) | 시간 복잡도 (평균) | 시간 복잡도 (최악) |
|---|---|---|---|---|
| 버블 정렬 | O(1) | O(n) | O(n^2) | O(n^2) |
| 힙 정렬 | O(1) | O(n log n) | O(n log n) | O(n log n) |
| 삽입 정렬 | O(1) | O(n) | O(n^2) | O(n^2) |
| 병합 정렬 | O(n) | O(n log n) | O(n log n) | O(n log n) |
| 퀵 정렬 | O(log n) | O(n log n) | O(n log n) | O(n^2) |
| 선택 정렬 | O(1) | O(n^2) | O(n^2) | O(n^2) |
📝 면접 예상 질문
Q: 대용량 데이터를 처리해야 할 때 어떤 자료구조를 선택하겠습니까? 그 이유는?
A: 해시 테이블을 선택할 것입니다. O(1)의 평균 검색/삽입/삭제 시간 복잡도로 대용량 데이터를 효율적으로 처리할 수 있기 때문입니다.
Q: 실시간으로 데이터를 정렬해야 하는 상황에서 어떤 정렬 알고리즘을 사용하겠습니까?
A: 힙 정렬을 사용하겠습니다. O(n log n)의 일관된 성능을 보이며, 실시간으로 들어오는 데이터를 정렬된 상태로 유지하기에 적합합니다.
Q: 데이터베이스 인덱싱에 사용되는 자료구조는 무엇이며, 왜 그 구조가 효율적인가요?
A: B-Tree나 B+Tree가 주로 사용됩니다. O(log n)의 검색/삽입/삭제 성능을 보이며, 디스크 기반 시스템에 최적화되어 있어 효율적입니다.
Q: 캐시 시스템 구현에 적합한 자료구조는 무엇이며, 그 이유는?
A: 해시 테이블이 적합합니다. O(1)의 빠른 접근 시간으로 캐시의 빠른 응답 시간 요구사항을 충족시킬 수 있습니다.
Q: 네트워크 패킷 처리나 작업 스케줄링에 자주 사용되는 자료구조는 무엇인가요?
A: 우선순위 큐(주로 힙으로 구현)입니다. O(log n)의 삽입/삭제 시간으로 효율적인 우선순위 기반 처리가 가능합니다.
✒️ 0. 들어가기 전
시간복잡도와 공간복잡도는 알고리즘의 효율성을 측정하는 중요한 개념이다.
시간복잡도는 알고리즘 실행 시간을, 공간복잡도는 필요한 메모리 공간을 나타낸다.
또한 빅오 표기법은 이러한 복잡도를 간단하게 표현하는 방법이다.
자료구조와 알고리즘에서 빠질 수 없는 복잡도(Complexity) ...
단순히 개념적으로만 알아둬야 할 게 아니고, 코딩테스트를 볼 때에도 꼭 알아둬야 할 파트이다.
너무 추상적인 복잡도는 항상 [런타임 에러]로 나를 괴롭혔다..
뿐만 아니라 코딩을 할 때 가장 신경써야 할 "효율" "성능" 개선에 빠질 수 없는 내용이다.
✒️ 1. 복잡도(Complexity)란?
알고리즘의 복잡도는 컴퓨터 과학에서 알고리즘의 성능을 평가하는 중요한 척도이다.
복잡도는 주로 시간 복잡도와 공간 복잡도로 구분된다.
이들은 각각 알고리즘의 실행 시간과 메모리 사용량을 나타낸다.
복잡도 분석은 알고리즘의 효율성을 객관적으로 평가하고 비교할 수 있게 해주는 핵심적인 도구이다.
간단하게 "이 알고리즘이 얼마나 효율적인가!?"
✒️ 2. 시간 복잡도 (Time Complexity)
시간 복잡도는 알고리즘이 문제를 해결하는 데 필요한 연산의 횟수를 의미한다.
이는 입력 크기에 따른 알고리즘의 실행 시간 증가율을 나타내며,
알고리즘의 효율성을 평가하는 가장 중요한 지표 중 하나이다.
시간 복잡도를 분석할 때는 주로 최악의 경우(worst-case)를 고려한다.
이는 알고리즘이 가장 오래 걸리는 경우를 대비하기 위함이다.
예를 들어, n개의 요소를 가진 배열에서 특정 요소를 찾는 선형 검색 알고리즘의 시간 복잡도는 O(n)이다.
최악의 경우, 찾고자 하는 요소가 배열의 마지막에 있거나 배열에 없을 때 n번의 비교 연산이 필요하기 때문이다.
반면, 정렬된 배열에서 이진 검색을 수행하는 경우, 시간 복잡도는 O(log n)이 된다.
이는 매 단계마다 검색 범위를 절반으로 줄이기 때문에, 입력 크기가 두 배로 증가할 때마다 필요한 연산의 수는 단 1회만 증가한다.
✒️ 3. 공간 복잡도 (Space Complexity)
공간 복잡도는 알고리즘이 실행되는 동안 사용하는 메모리의 양을 나타낸다.
이는 입력 데이터를 저장하는 데 필요한 고정 공간과 알고리즘이 실행되면서 추가로 사용하는 가변 공간으로 구성된다.
예를 들어, n개의 정수를 입력받아 그 합을 계산하는 간단한 알고리즘의 공간 복잡도는 O(1)이다.
입력의 크기에 관계없이 합을 저장할 변수 하나만 필요하기 때문이다.
반면, n x n 행렬의 곱셈을 계산하는 알고리즘의 공간 복잡도는 O(n^2)이다.
결과를 저장할 n x n 크기의 새로운 행렬이 필요하기 때문이다.
💡 시간 복잡도와 공간 복잡도의 관계
시간 복잡도와 공간 복잡도는 반비례하는 경향이 있다. (Trade-Off)
시간을 절약하기 위해 더 많은 공간을 사용하거나, 반대로 공간을 절약하기 위해 더 많은 시간을 소비하는 경우가 많다.
또한, 최근에는 메모리 비용이 상대적으로 저렴해져 시간 복잡도에 비해 공간 복잡도의 중요성이 다소 낮아졌다.
그러나 대용량 데이터를 다루는 빅데이터 분야나 제한된 자원을 가진 임베디드 시스템에서는 여전히 공간 복잡도가 중요한 고려 사항이다.
✒️ 4. 빅오 표기법 (Big-O Notation)
빅오 표기법은 알고리즘의 복잡도를 간단하고 일반화된 형태로 표현하는 방법이다.
이 표기법은 입력 크기가 무한히 커질 때 알고리즘의 성능을 나타내며, 가장 빠르게 증가하는 항만을 고려한다.
빅오 표기법의 주요 특징은 다음과 같다:
1. 상수항 무시: O(2n)은 O(n)으로 표기한다.
2. 계수 무시: O(3n^2)도 O(n^2)로 표기한다.
3. 낮은 차수 무시: O(n^2 + n)은 O(n^2)로 표기한다.
이러한 특징들로 인해 빅오 표기법은 알고리즘의 효율성을 대략적으로 비교하는 데 매우 유용하다.
✒️ 5. 시간 복잡도 & 빅오 표기법
시간 복잡도는 특정 크기의 입력(n)을 기준으로 실행하는 연산의 횟수.
-> 핵심이 되는 연산의 횟수만 세면 된다.
물론 코드를 보고 시간 복잡도를 구하는 문제도 [자료구조] 수업에서 많이 풀었었는데,
예제를 다루지는 않겠다.
| 복잡도 | 소요 시간 | 예시 |
|---|---|---|
| O(1) | 상수 시간 | - 스택에서 Push, Pop - 배열의 인덱스 접근 - 해시 테이블의 삽입/조회 (평균 경우) => dictionary 등 사용 권장 |
| O(log n) | 로그 시간 | - 이진 검색 - 균형 이진 트리의 검색/삽입/삭제 - 힙(Heap)의 삽입/삭제 => heapq 사용 권장 |
| O(n) | 선형 시간 | - 단일 for 문 - 선형 검색 - 단일 연결 리스트의 순회 |
| O(n log n) | 선형 로그 시간 | - 퀵 정렬(평균 경우) - 병합 정렬 - 힙 정렬 - 효율적인 비교 기반 정렬 알고리즘 |
| O(n^2) | 2차 시간 | - 이중 for 문 (중첩 for 문의 개수에 따라 n의 x제곱이 된다.) - 버블 정렬 - 선택 정렬 - 삽입 정렬 |
| O(2^n) | 지수 시간 | - 부분 집합 생성 - 피보나치 수열(재귀 구현) - 외판원 문제(브루트 포스) |
| O(n!) | 팩토리얼 시간 | - 순열 생성 - 여행 경로 문제(모든 경우의 수) |
💡 자료구조별 시간 복잡도
| 자료구조 | 검색 (평균) | 삽입 (평균) | 삭제 (평균) | 검색 (최악) | 삽입 (최악) | 삭제 (최악) |
|---|---|---|---|---|---|---|
| 배열 | O(n) | N/A | N/A | O(n) | N/A | N/A |
| 정렬된 배열 | O(log n) | O(n) | O(n) | O(log n) | O(n) | O(n) |
| 연결 리스트 | O(n) | O(1) | O(1) | O(n) | O(1) | O(1) |
| 이중 연결 리스트 | O(n) | O(1) | O(1) | O(n) | O(1) | O(1) |
| 스택 | O(n) | O(1) | O(1) | O(n) | O(1) | O(1) |
| 해시 테이블 | O(1) | O(1) | O(1) | O(n) | O(n) | O(n) |
| 이진 검색 트리 | O(log n) | O(log n) | O(log n) | O(n) | O(n) | O(n) |
| B-Tree Red-Black Tree AVL Tree |
O(log n) | O(log n) | O(log n) | O(log n) | O(log n) | O(log n) |
💡 정렬 알고리즘별 복잡도
| 정렬 알고리즘 | 공간 복잡도 | 시간 복잡도 (최선) | 시간 복잡도 (평균) | 시간 복잡도 (최악) |
|---|---|---|---|---|
| 버블 정렬 | O(1) | O(n) | O(n^2) | O(n^2) |
| 힙 정렬 | O(1) | O(n log n) | O(n log n) | O(n log n) |
| 삽입 정렬 | O(1) | O(n) | O(n^2) | O(n^2) |
| 병합 정렬 | O(n) | O(n log n) | O(n log n) | O(n log n) |
| 퀵 정렬 | O(log n) | O(n log n) | O(n log n) | O(n^2) |
| 선택 정렬 | O(1) | O(n^2) | O(n^2) | O(n^2) |
📝 면접 예상 질문
Q: 대용량 데이터를 처리해야 할 때 어떤 자료구조를 선택하겠습니까? 그 이유는?
A: 해시 테이블을 선택할 것입니다. O(1)의 평균 검색/삽입/삭제 시간 복잡도로 대용량 데이터를 효율적으로 처리할 수 있기 때문입니다.
Q: 실시간으로 데이터를 정렬해야 하는 상황에서 어떤 정렬 알고리즘을 사용하겠습니까?
A: 힙 정렬을 사용하겠습니다. O(n log n)의 일관된 성능을 보이며, 실시간으로 들어오는 데이터를 정렬된 상태로 유지하기에 적합합니다.
Q: 데이터베이스 인덱싱에 사용되는 자료구조는 무엇이며, 왜 그 구조가 효율적인가요?
A: B-Tree나 B+Tree가 주로 사용됩니다. O(log n)의 검색/삽입/삭제 성능을 보이며, 디스크 기반 시스템에 최적화되어 있어 효율적입니다.
Q: 캐시 시스템 구현에 적합한 자료구조는 무엇이며, 그 이유는?
A: 해시 테이블이 적합합니다. O(1)의 빠른 접근 시간으로 캐시의 빠른 응답 시간 요구사항을 충족시킬 수 있습니다.
Q: 네트워크 패킷 처리나 작업 스케줄링에 자주 사용되는 자료구조는 무엇인가요?
A: 우선순위 큐(주로 힙으로 구현)입니다. O(log n)의 삽입/삭제 시간으로 효율적인 우선순위 기반 처리가 가능합니다.