
✒️ 0. 들어가기 전
이번 글에서는 연결리스트, 스택, 큐와 같은 기본적인 자료구조에 대해 깊이 있게 탐구해보겠다.
각 자료구조의 개념, 구조, 시간 복잡도, 그리고 실전 코드 예제까지 다루면서 그 원리를 이해하고, 어떻게 구현되고 사용하는지를 배워보자.
✒️ 1. 연결리스트(Linked List)
연결리스트는 메모리에서 연속되지 않은 위치에 노드를 저장하며, 각 노드는 다음 노드로의 포인터를 가지고 있다.
이는 배열과 같은 순차적인 자료구조와는 다르게, 삽입과 삭제가 빠르게 이루어질 수 있는 장점을 제공한다.
노드는 데이터와 다음 노드를 가리키는 포인터로 구성되며, 이 포인터를 통해 노드들이 연결된다.
각 노드는 next 또는 next, prev라는 포인터로 서로 연결된 선형적인 자료구조!!
연결리스트는 주로 데이터의 삽입과 삭제가 빈번한 상황에서 사용된다.

💡 시간 복잡도
- 참조 : O(n)
- 탐색 : O(n)
- 삽입 / 삭제 : O(1)
💡 연결리스트의 종류
1. 싱글 연결리스트(Singly Linked List)

싱글 연결리스트는 각 노드가 오직 다음 노드를 가리키는 포인터(next)만을 가지고 있다.
노드를 탐색할 때는 첫 번째 노드부터 시작하여 차례로 다음 노드를 따라가야 하므로,
특정 위치의 노드를 찾는 데 O(n)의 시간이 소요된다.
하지만 노드의 삽입과 삭제는 O(1)의 시간 복잡도를 가진다.
class Node {
public:
int data;
Node* next;
Node(int data) : data(data), next(nullptr) {}
};
2. 이중 연결리스트(Doubly Linked List)

이중 연결리스트는 각 노드가 다음 노드(next)와 이전 노드(prev)를 가리키는 두 개의 포인터를 가지고 있다.
따라서 양방향으로 탐색이 가능하며, 노드의 삽입과 삭제 시에도 해당 노드의 이전 노드를 쉽게 접근할 수 있어 더 유연하게 사용할 수 있다.
class Node {
public:
int data;
Node* next;
Node* prev;
Node(int data) : data(data), next(nullptr), prev(nullptr) {}
};
3. 원형 연결리스트(Circular Linked List)
원형 연결리스트는 마지막 노드가 첫 번째 노드를 가리키도록 구성된 연결리스트이다.
이를 통해 리스트의 끝에서 시작으로 다시 돌아가는 구조를 가지게 된다.
원형 연결리스트는 싱글 또는 이중 연결리스트로 구현될 수 있다.


// 원형 싱글 연결리스트 예시
class Node {
public:
int data;
Node* next;
Node(int data) : data(data), next(nullptr) {}
};
void createCircular(Node* head) {
Node* temp = head;
while (temp->next != nullptr) {
temp = temp->next;
}
temp->next = head; // 마지막 노드가 첫 노드를 가리키도록
}
💡 랜덤(직접)접근과 순차적 접근

직접 접근이라고 하는 랜덤 접근(random access)은 동일한 시간에 배열과 같은 순차적인 데이터가 있을때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능이다.
이는 데이터를 저장된 순서대로 검색해야 하는 순차적 접근(sequential access)과는 반대이다.
vector, Array와 같은 배열은 랜덤접근이 가능해서 n번째 요소에 접근할 때 O(1)이 걸리며
연결리스트, 스택, 큐는 순차적 접근만이 가능해서 n번째 요소에 접근할 때 O(n)이 걸린다.
💡 언제 사용해야 할까?
>> 연결리스트는 요소의 추가와 삭제가 빈번히 일어나는 상황에 적합하지만,
임의의 요소에 접근하는 데 시간이 많이 소요되므로, 랜덤 접근이 자주 요구되는 경우에는 적합하지 않다.
✒️ 2. 스택(Stack)
스택은 후입선출(LIFO, Last In First Out) 구조를 가진 자료구조이다.
이것이 가장 큰 특징이기 떄문에, 이를 기억하고 있으면! 다른 부분이 자연스럽게 이해될 것이다.
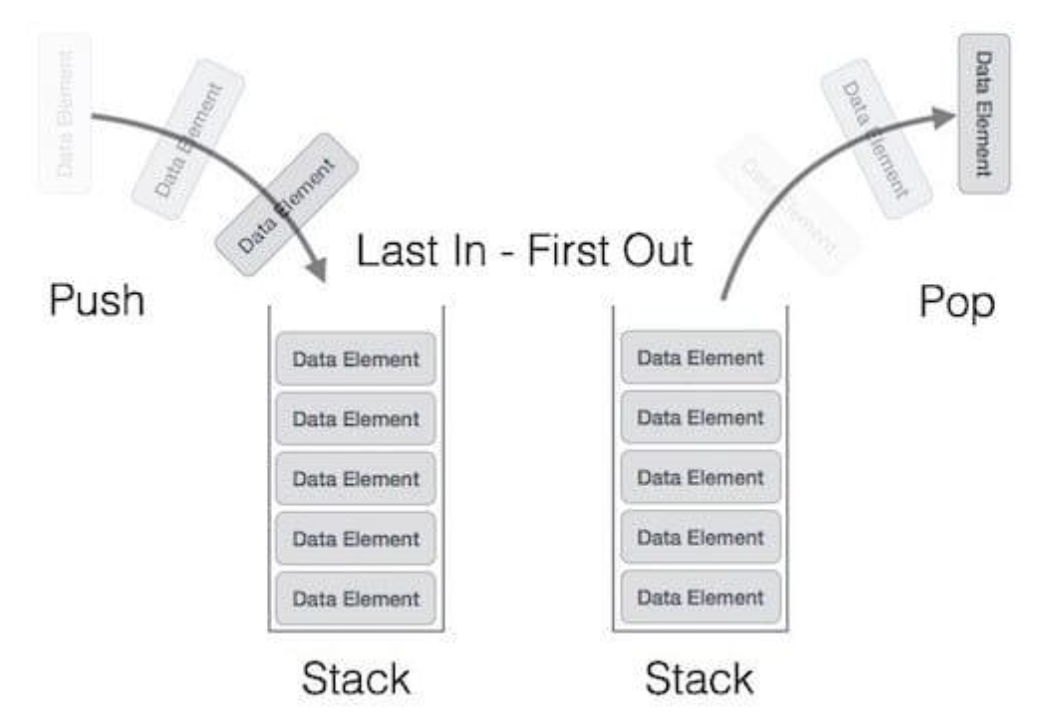
이는 가장 마지막에 추가된 요소가 가장 먼저 제거되는 구조이다!!!
자연스럽게 생각해보면, 마지막 한 행위를 다시 끄집어 낼 때 사용하면 좋을 것 같다.
예를 들어, 웹 브라우저의 방문 기록이나 텍스트 에디터의 되돌리기 기능 등이 스택을 활용한 대표적인 사례이다.
💡 시간복잡도
- n번째 참조: O(n)
- 가장 앞부분 참조: O(1)
- 탐색: O(n)
- 삽입/삭제(n번째 제외): O(1)
💡 스택의 구현
스택은 연결리스트나 배열을 기반으로 구현할 수 있다.
연결리스트 기반의 스택은 동적으로 메모리를 할당하여, 메모리 크기에 제한 없이 사용할 수 있는 반면,
배열 기반의 스택은 고정된 크기의 메모리를 사용하므로, 스택의 크기가 초과하면 오버플로우가 발생할 수 있다.
#include <stack>
#include <iostream>
int main() {
std::stack<std::string> stk;
stk.push("엄");
stk.push("준");
stk.push("식");
while (!stk.empty()) {
std::cout << stk.top() << "\n";
stk.pop();
}
return 0;
}
위의 예제에서는 엄, 준, 식 을 차례로 스택에 푸시(push)하고, 스택이 비어질 때까지 팝(pop)하면서 출력한다.
결과는 스택의 특성에 따라 식, 준, 엄의 순서로 출력된다.
💡 언제 사용해야 할까?
>> 스택은 주로 함수 호출 관리, 깊이 우선 탐색(DFS), 그리고 뒤로 가기와 같은 기능에서 중요한 역할을 한다.
✒️ 3. 큐(Queue)
큐는 반대로 선입선출(FIFO, First In First Out) 구조를 가진 자료구조이다.
<편의점 알바를 한 번이라도 해보았으면 아는 "선입선출"!>

그렇다면 자연스럽게 큐는 순서를 보장하면서 데이터가 처리되도록 하는 데 강점을 가지고 있다고 이해할 수 있다.
즉, 먼저 들어간 데이터가 먼저 나오는 구조로, 프로세스 관리, 네트워크 데이터 처리, 너비 우선 탐색(BFS) 등에 자주 사용된다.

💡 시간 복잡도
- n번째 참조: O(n)
- 가장 앞부분 참조: O(1)
- 탐색: O(n)
- 삽입/삭제(n번째 제외): O(1)
💡 큐의 구현
큐는 배열이나 연결리스트를 이용해 구현할 수 있다.
배열을 사용한 큐는 고정된 크기 때문에 크기가 제한되지만,
연결리스트 기반 큐는 동적으로 메모리를 할당할 수 있어 유연하게 사용할 수 있다.
#include <queue>
#include <iostream>
int main() {
std::queue<int> q;
for (int i = 1; i <= 10; i++) {
q.push(i);
}
while (!q.empty()) {
std::cout << q.front() << ' ';
q.pop();
}
return 0;
}위의 코드에서는 1부터 10까지의 정수를 큐에 차례로 푸시하고, 큐가 비어질 때까지 팝하면서 출력한다.
큐는 선입선출 구조이므로 출력 결과는 1 2 3 4 5 6 7 8 9 10이 된다!
💡 언제 사용해야 할까?
>> 큐는 대기열이나 작업 순서가 중요한 프로세스 관리에서 유용하게 사용된다.
예를 들어, 운영체제의 작업 스케줄링이나 네트워크 패킷 처리에서 큐가 중요한 역할을 한다.
📝 면접 예상 질문
Q: 연결리스트와 배열의 차이점은 무엇인가요?
A: 연결리스트는 메모리에서 연속적이지 않은 위치에 노드가 저장되며, 각 노드는 다음 노드의 주소를 가리키는 포인터를 포함합니다. 배열은 메모리에서 연속된 위치에 데이터가 저장되며, 인덱스를 통해 빠르게 접근할 수 있습니다. 연결리스트는 삽입과 삭제가 용이하지만, 특정 요소에 접근하는 데 O(n)의 시간이 걸리고, 배열은 접근이 O(1)이지만, 삽입과 삭제는 O(n)이 걸립니다.
-> 데이터 추가와 삭제를 많이 하는 것은 연결 리스트, 참조를 많이 하는 것은 배열로 하는 것이 좋습니다.
Q: 연결리스트에서 마지막 노드를 찾기 위해 필요한 시간 복잡도는 무엇인가요?
A: 연결리스트에서 마지막 노드를 찾기 위해서는 첫 번째 노드부터 순차적으로 접근해야 하므로 시간 복잡도는 O(n)입니다.
Q: 스택이 실무에서 주로 사용되는 예시는 무엇인가요?
A: 스택은 재귀 함수의 호출 스택 관리, 웹 브라우저의 뒤로 가기 기능, 텍스트 편집기의 되돌리기 기능 등에서 사용됩니다. 함수 호출 시에는 호출 스택에 함수가 추가되고, 함수가 종료되면 스택에서 제거됩니다.
Q: 스택을 배열로 구현할 때 발생할 수 있는 문제점은 무엇인가요?
A: 스택을 배열로 구현할 경우, 스택의 크기가 고정되어 있어 스택이 가득 차면 오버플로우(Overflow) 문제가 발생할 수 있습니다. 이는 배열의 크기를 초과하여 더 이상 요소를 추가할 수 없음을 의미합니다.
Q: 큐와 스택의 차이점은 무엇인가요?
A: 큐는 선입선출(FIFO) 구조로, 먼저 들어간 데이터가 먼저 나오고, 스택은 후입선출(LIFO) 구조로, 나중에 들어간 데이터가 먼저 나옵니다. 큐는 주로 작업 스케줄링이나 데이터 흐름 제어에 사용되고, 스택은 함수 호출 관리나 알고리즘에서 사용됩니다.