
-
0. 들어가기 전
-
1. 클라우드 환경이라는 것이 정확히 어떤 의미인가?
-
1-1. 클라우드가 기존 온프레미스 환경과 어떻게 다른가?
-
1-2. 가상화
-
2. 컨테이너와 도커
-
2-1. 컨테이너
-
2-2. 도커
-
3. 도커 컨테이너 기반의 배포 방식
-
3-1. 기존 배포 방식 (EC2에 소스코드 직접 배포하기)
-
3-2. 도커 컨테이너 기반 배포 방식 : Dockerfile
-
4. Docker? Docker-Compose? Kubernates?
-
4-1. Docker Compose
-
4-2. Kubernates (K8s)
-
5. 실제 CI/CD 파이프라인 Flow
-
5-2. GitLab과 GitLab Runner
-
5-3. CI/CD 전체적인 흐름
-
5-4. 참고 : 소스코드 배포의 CI 과정 (컨테이너 X)
-
+ 서비스의 분류 체계
-
✅ 컨테이너 오케스트레이션 도구
-
✅ CI/CD 배포 자동화 도구
-
✅ 인프라 서비스 (서버/네트워크)
세부적인 설명에도 전체 그림이나 Flow 등이 머리 속에 들어오지 않아
시간을 내어 정리하는 시간을 가지고 싶었습니다.
저처럼 서버 개발은 해보았지만, 클라우드에 대해 입문 하시는 분들은 다음 글을 읽어보시면 도움이 되실 것 같습니다.
0. 들어가기 전
클라우드 과정을 짧은 기간에 공부하다 보니, 다음과 같은 질문들이 마구마구 지나가기 시작했다.
도커와 컨테이너의 정의가 정확히 어떻게 되지?
이미지와 컨테이너? 대충은 객체와 인스턴스 느낌인데 정확히 어떻게 돌아가는 거지?
도커를 사용하면 기존 EC2에 소스코드를 올리는 방식은 어떻게 다르지?
CI/CD 파이프라인의 정확한 동작 Flow는 어떻게 되는거지
젠킨스, 깃허브 액션 등 툴이 너무 많으니 분류 기준이 머리 속에 확립이 안된다..
왜 기업들은 사내망에서 GitLab을 더 많이 사용하는걸까?
허브? 레지스트리? 왜 이미지를 외부에 저장하는 과정이 필요하지?
EKS, ECS ? 실제 AWS에서 제공하는 컨테이너 관련 서비스는 어떻게 다루는거지?
쿠버네티스는 정확히 인프라인가? 어떠한 툴인가? 하나의 환경인가?
너무 많은 의문점들이 머리 속을 헤매기 시작했다.
먼저 대단원을 소개하면,
- 클라우드와 컨테이너 개념
- 컨테이너 기반 배포와 CI/CD에 관해
- 클라우드 네이티브 아키텍처와 AWS에 대해 연결해 이해해보자.
끝으로 쿠버네티스에 대한 개념을 연결해서 정리하면,
이후 클라우드 공부하는 데 머리 속에 큰 틀은 잡혀있을 것이다.
1. 클라우드 환경이라는 것이 정확히 어떤 의미인가?
1-1. 클라우드가 기존 온프레미스 환경과 어떻게 다른가?
결론부터 말하면, 클라우드란 "컴퓨터 자원을 더 유연하게 제공하는 방식" 이라고 이해하면 편하다.
먼저 전통적인 IT 인프라 방식과 비교하면 좋다.
클라우드가 등장한 이유
만약 자체적으로 온프레미스 환경으로 사내에서 직접 서버를 구축한다고 가정해보자.
- 데이터 센터에 서버를 구매하고 설치한다.
- 네트워크를 구축하고, 스토리지를 구성한다.
- 방화벽, 보안 규칙 등의 보안 설정을 한다.
- 장애가 발생하면 직접 노트북을 연결하여 CLI로 직접 장애 대응을 한다.
- 이후 끊임없는 유지 보수가 필요하다.
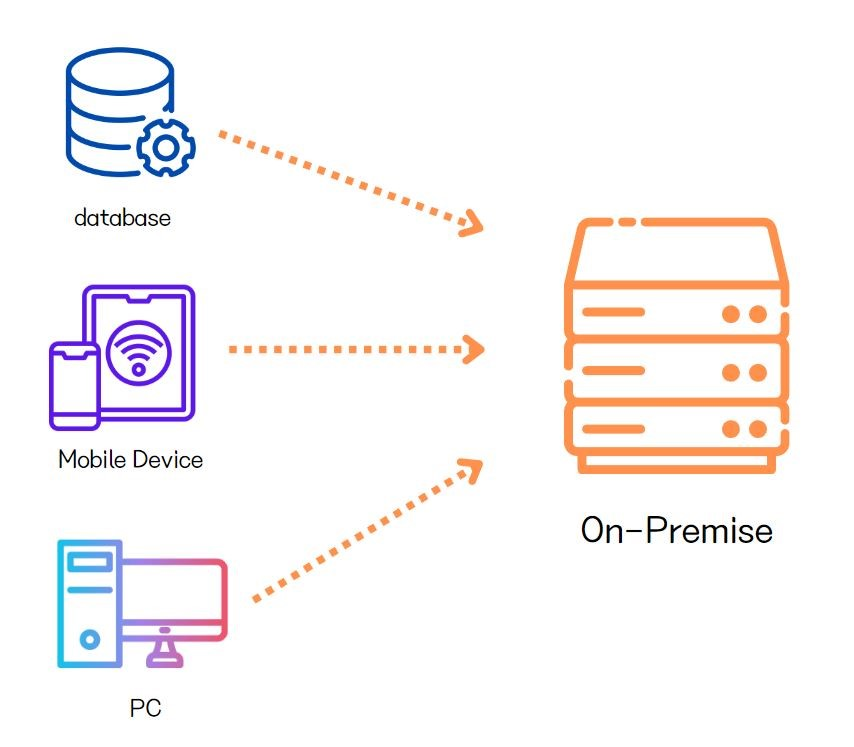
물론 규모가 작은 회사나, 클라우드 비용을 장기적으로 아끼고 싶다면 충분히 고려할 수 있는 옵션이지만
기본적으로 초기 비용이 비싸고, 유지 보수가 어려우며 확장성이 제한적 이라는 명확한 단점이 있다.
이럴 때 클라우드 제공업체에게 서버를 빌려쓰고 반납하는 개념을 "클라우드"라고 한다.
(가장 대표적인 제공업체는 AWS, Azure 등이 있다.)

클라우드에서는 클릭 몇 번으로 서버를 만들고, 필요하면 바로 확장할 수 있다.
즉, 비용과 유지보수 부담을 줄이면서, 유연하게 인프라를 운영할 수 있는 방식이라고 보면 된다.
1-2. 가상화
클라우드/ 컨테이너에 개념을 이해하려면 가상화만 이해하면 된다.
가상화
가장 중요한 개념은 "가상화"이다.
초반에 말했듯 과거에는 "물리 서버 1대 = 서비스 1개" 였고, 그에 따른 어려움이 있었다.
예를 들어 이런 상황을 생각해보자.
현재 본인의 컴퓨터에서 Java 17, MySQL 8.0 으로 서비스를 돌리고 있다.
그런데, 추가 서비스를 다른 부서가 만들었고, 그 서비스와 통합하려고한다.

애초에 계획되지 않은 통합이었기에, 해당 부서는 Java 11, MySQL 5.7 을 사용하고 있었고,
의존성 문제, 포트 충돌에 설정 관리에, 경로 문제까지 마구마구 문제가 터져나왔다...
마구마구 충돌~~~~~

그럼 그냥 이런 생각을 할 수 있다.
'아, 그냥 다른 환경에서 돌아갈 수 있도록 컴퓨터를 하나 더 사자!'
(단순한 해결책일 수록 돈이 많이 든다..)

그래서 내 컴퓨터 하나에 각각 다른 환경을 나누고 싶은 생각이 들었다.
(마치 내 컴퓨터 하나를 여러 개의 컴퓨터로 쪼개듯)

→ Host OS 위에 여러 개의 (가상 머신)VM을 띄우고, 버전에 맞는 각 OS 위에 앱들을 띄운다.
이것이 Hypervisor의 가상화 기술이다.
즉, [가상화]라는 것은
VM이나 이후에 나올 컨테이너 등에 대한 포괄적인 IT 개념이며,
물리적인 공간을 논리적으로 나눈다는 뜻이다.
(V-LAN도 마찬가지)
쉽게 한 층에 가벽을 세워서 공간을 나누는 모습을 생각하면 편하다.

사실 Virtual Box나 VM Ware 설치하고 우분투를 설치해본 분들이라면 무슨 느낌인지 바로 아실 것이다.
하지만 가상 머신은 격리/독립된 환경에서 각기 다른 앱들을 돌릴 수 있다는 장점이 있지만,
애뮬레이터, OS의 부팅 등 VM 환경은 상당히 무거웠고,
또한 어플리케이션의 확장에 한계가 있었다.
2. 컨테이너와 도커
2-1. 컨테이너
어플리케이션 하나 돌리려고, 가상 머신을 돌리는 것은 마치 이사할 때마다 가벽을 각각 짓는 것과 같다..
(그냥 방을 하나 더 짓는 격)

그래서 가상 머신 방식보다 더 가볍고 빠른 방식이 탄생한다.
그냥 "필요한 모든 것을 박스에 담아서 환경에 구애 받지 않도록 하면 되잖아"
컨테이너는 OS 자체를 가상화 하는게 아니라 Host OS 위에서 가벼운 프로세스 형태로 돌아가기 때문에 훨씬 빠르고 가볍다.
또한, 하나의 OS 위에서 여러 개의 어플리케이션을 독립적으로 실행시킬 수 있다.
이를 OS 수준에서 격리가 가능하기 때문에 서로 충돌 없이 동작 한다.
<참고로, 컨테이너는 원래 리눅스의 네임스페이스(namespaces)와 cgroups(control groups)라는 기술을 기반으로 프로세스를 격리하는 개념이다.>
즉, 우리가 빌린 EC2 서버에서 여러 개의 서비스를 컨테이너로 격리시켜 돌릴 수 있다는 것이다.
2-2. 도커
컨테이너의 개념은 사실 리눅스에서 예전부터 나온 개념이지만,
이를 실제 애플리케이션에 적용하고 실용화 시킨 것은 [Docker]이다.
기존에는 컨테이너 환경을 직접 설정해야 했지만,
도커는 명령어 몇 개 만으로 컨테이너 실행이 가능하도록 한다.

또한 도커를 이용해 컨테이너를 패키징하고, 배포하고, 실행하는 모든 과정을 자동화할 수 있다.
(Dockerfile 혹은 Docker-Compose)
오해하면 안되는 것이 "도커"가 "컨테이너" 자체는 아니다.
도커는 "컨테이너 기술에 여러 기능을 추가한 오픈소스 프로젝트"이다.
그렇다면 도커의 핵심 요소에서 이미지, 컨테이너, 허브는 정확히 어떤 의미일까..?
도커 이미지
- 실행 가능한 컨테이너를 만들기 위한 템플릿이다!
(붕어빵 틀)
도커 컨테이너
- 도커 이미지에서 실행된 어플리케이션이다!
(리얼 구워서 나온 붕어빵 실체)
=> 쉽게 말하면 "도커 이미지(Image)와 컨테이너(Container) 관계는 클래스(Class)와 인스턴스(Instance) 관계랑 똑같다!"
도커 허브 [레지스트리]
- 이미지를 공유할 수 있는 저장소이다.
=> 깃 허브랑 이름이 비슷하다.
맞다. 깃허브는 소스코드를 저장하는 저장소라면, 도커허브는 도커 이미지를 저장하는 저장소이다.
미리 Flow를 말해주자면,
GitHub에서 소스 코드 저장
-> 작성된 Dockerfile을 통해 소스코드를 기반으로 Docker 이미지 빌드
-> Docker Hub에 업로드
-> OS에서 다운로드 하여 실행
또한 "도커 허브"는 하나의 도커 레지스트리 라는 점을 알아 두자.
3. 도커 컨테이너 기반의 배포 방식
3-1. 기존 배포 방식 (EC2에 소스코드 직접 배포하기)
기존 방식은 EC2(가상 서버)를 대여한 뒤, 소스코드를 직접 올려 실행하는 방식이다.
서비스를 한 번이라도 올려봤다면 다들 익숙한 방법일 것이다.
- AWS에서 EC2 인스턴스 생성
- SSH로 EC2에 접속
- 필요 패키지 및 라이브러리 해당 EC2에 설치
- 소스코드 직접 올리기
- 실행 스크립트 작성
-> 서버 마다 다른 환경 때문에 다른 환경으로 옮길 때 문제가 잦다
배포할 때마다 환경 설정을 매번 다시 해야 한다.
확장이 어렵다 등의 단점이 있다.
그렇다면 컨테이너 기반의 배포 방식은 어떻게 다를까
3-2. 도커 컨테이너 기반 배포 방식 : Dockerfile
'컨테이너 기반 배포'라는 것은 EC2를 운영체제의 단위로 사용하는 것이 아니라, 컨테이너 단위로 격리하여 실행한다.
도커 컨테이너 자체가 앱이 실행되는 가벼운 가상 머신의 역할을 하기 때문이다.
CI/CD를 적용하지 않은 수동 배포 방식에 대해 먼저 알아보자.
1. Dockerfile 생성
- 컨테이너를 어떻게 만들어야 하는지를 설명하는 설명서 혹은 레시피 작성 => 결과물은 '이미지'가 나온다.
(이미지를 실행하면 컨테이너가 가동 된다고 했습니다.)
- 필요한 파일과 의존성이 명시되어 있고, 환경 변수 설정과 스크립트가 작성되어 있다.
- 명령어들이 layer 형태로, 순차적으로 실행되기 때문에 자주 변경되지 않는 파일부터 작성한다.
2. Image build
- Dockerfile을 이용해서 이미지를 만든다.
- 어플리케이션의 스냅샷 (이미지가 생성된 그 순간의 프로젝트의 상태를 의미)
- 어플리케이션을 실행하는데 필요한 모든 정보를 포함한다. (불변의 상태)
3. 이미지를 컨테이너 레지스트리에 push
컨테이너 레지스트리는 public, private로 나뉜다.
대표적인 public Registry에 Docker Hub가 있다고 했다.
Private Registry에는 AWS, Azure 등에서 제공하는 레지스트리 도 있다.
4. 이미지를 pull 받아서 컨테이너를 실행
- 이미지의 인스턴스
- 이미지를 통해서 컨테이너를 생성하고 고립된 환경(EC2 등의 빌린 가상 서버)에서 실행한다.
-> docker run 한 줄이면 배포 완료 가능!
서비스 - 컨테이너 - 가상 서버의 관계
나는 이 내용을 듣다가 두 가지 궁금증이 들었다.
- 서비스 규모가 작으면 한 컨테이너에 다 갖다 박아도 되나..?
- 만약에 각각 한 컨테이너로 나눈다면, 한 EC2에 올리나? 여러 EC2에 올리나?
먼저, One Process per Container 원칙에 맞게, 한 서비스는 한 컨테이너에 담는 것이 원칙이다.
확장이 불가능하며, 하나의 서비스가 죽으면 모두 꺼지기 때문이다.
(서비스 별 로그 / 장애 관리 등... 길게 설명하지 않겠다.)
허나 2번의 질문은 서비스 규모와 운영 방식에 따라 다르게 선택해도 된다고 생각한다.
단일 서비스이고, 작은 서비스라면 충분히 한 EC2에 여러 컨테이너를 올려도 괜찮다고 생각한다.
특히 "docker-compose up -d" 한 번으로 모든 서비스가 한 서버에서 동작할 수 있기 때문이다.
또한, 64기가 서버를 AWS에서 대여한다고 했을 때,
4기가 짜리 서비스, 1기가 짜리 레디스 서비스 등을 따로 돌리는 것이 오히려 가격적으로 손해이기 때문이다.

허나 트래픽이 많거나, MSA 구조에서는 컨테이너를 자동 분산하는 것을 추천한다.
<꼭 한 서버가 하나의 컨테이너가 아니더라도 서버를 나누어 분하 분산을 해준다.>
(이 때 AWS의 ECS, EKS(쿠버네티스) 등을 사용한다.)
하나의 EC2가 다운되더라도 전체 서비스가 죽지 않도록 하는 것이 중요하기 때문이다.

4. Docker? Docker-Compose? Kubernates?
도커와, 도커를 사용하여 배포하는 것은 대충 어떤식으로 이루어지는 알아 보았다.
도커는 개별 컨테이너를 만들고 실행하는 도구이라고 하였다.
허나, 도커만 사용하면 하나의 애플리케이션 컨테이너는 실행할 수 있지만, 여러 개의 컨테이너를 관리하기 어렵다.
4-1. Docker Compose
이를테면, 실제 웹 애플리케이션을 배포한다고 생각해보자.
웹 서버(Nginx) + DB(MySQL) + 캐시(Redis)가 필요할 수도 있고, 이 컨테이너들을 관리할 것인가?
도커 컴포즈는 여러 개의 컨테이너를 한 번에 실행하고 관리할 수 있는 도구이다.
컨테이너가 많아질수록 관리가 힘들어진다.
하나의 컨테이너를 어떻게 만들어야 하는지를 설명하는 설명서 혹은 레시피를 Dockerfile이라고 하였다.
docker-compose은 여러 개의 컨테이너를 정의하고 한 번에 실행할 수 있는 파일 이다.
[예시 : 웹서버 + DB]
version: "3"
services:
web:
image: nginx
ports:
- "8080:80"
db:
image: mysql
environment:
MYSQL_ROOT_PASSWORD: example
바로 위에서 나온 "docker-compose up -d"로 한 번에 모든 컨테이너를 실행할 수 있다.
그런데 이런 생각이 든다.
바로 위에서 트래픽이 매우 많거나, MSA 구조에서는 컨테이너를 자동 분산하는 것을 추천한다고 하였다.
(이 때 AWS의 ECS, EKS(쿠버네티스) 등을 사용한다.)
그런데, 이렇게 여러 서버에 여러 개의 컨테이너가 띄워져있는 환경이라면,
Docker-Compose 만으로는 여러 서버를 관리하기 어려울 것이다.
또한, 만약 분산 부하를 관리해주는 툴을 사용한다면, 저 수많은 컨테이너들은 이 서버 저 서버를 옮겨다닐 것이다.
그래서 등장한 것이 쿠버네티스 이다.
4-2. Kubernates (K8s)
쿠버네티스는 컨테이너를 대량으로 운영할 때 필요한 오케스트레이션(Orchestration) 도구이다.
확실히 필요한 이유는 [도커나 도커 컴포즈는 한 서버에서만 컨테이너를 관리할 수 있다]는 한계가 있기 때문이다.
동적으로 늘어나는 트래픽에 동적으로 늘어나는 인스턴스와 컨테이너의 개수를 개발자가 관리하는 것에는 한계가 있다.
이러한 오케스트레이션 도구는
여러 서버에 있는 여러 컨테이너들을 관리해주고,
서버 장애가 나도 자동으로 컨테이너를 재시작하고,
로드 밸런싱도 자동으로 처리하는 등의 역할을 한다.
그럼 '쿠버네티스'라는 것이 정확히 어떤 개념에 속하는 걸까?
(이런 분류 체계의 개념을 잡는 것이 처음에 너무 어려웠다..)

K8S는 IaaS인가? 인프라인가? 툴인가? 환경인가?
- 먼저, 쿠버네티스 자체로써 서버의 기능은 제공하고 있지 않기 때문에, Infa as a Service라고 보기는 어렵다.
- 인프라 자체가 아닌 "컨테이너를 관리하는 소프트웨어(툴)"이라고 볼 수 있다.
- 이전에 보았던, 여러 대의 서버<노드>들에 여러 컨테이너가 띄워져있는 것을 쿠버네티스 클러스터라고 하는데,
이 클러스터 자체는 일종의 '컨테이너 운영 환경'이라고 볼 수 있다.
우리는 SpringBoot를 배울 때 IoC라는 것을 배웠다.
제어의 역전은 기존의 개발 방식에서 개발자가 직접 제어 흐름을 제어하는 것이 아니라,
외부의 프레임워크나 라이브러리가 제어 흐름을 대신해주는 것으로 이해하고 있다.
점점 자동화와 개발자가 비즈니스 로직에만 집중할 수 있도록 해주는 툴이 발전중이다.
노드 (Node)
또 이런 의문점이 든다.
쿠버네티스에서 중요한 요소인 Node(노드) 는 서버인데, 서버의 기능이 없다?
- 쿠버네티스 자체는 서버를 생성하고 관리하는 기능은 아예 없다.
하지만, 이미 존재하는 노드 위에서 컨테이너를 띄우고 관리하는 역할을 하는 것이다.
즉, 마스터 노드, 워커 노드 에서 쓰이는 용어인 노드는
쿠버네티스가 컨테이너를 실행할 "작업 공간"을 제공하는 서버(EC2, VM, 물리 서버)이다.
클러스터 안에서 노드를 관리하는 것은 맞지만, 직접 생성하거나 운영하지 않는다.
그렇다면, 쿠버네티스가 노드와 상호작용 하는 것은 어떤 것이 있을까?
간단히만 알아보자.
- 노드가 추가되면 새로운 컨테이너를 배치
- 노드가 장애가 나면 컨테이너를 다른 노드로 옮김
- 트래픽 증가 시 노드에 새로운 컨테이너를 배포
ECS? EKS?
쿠버네티스와 함께 자주 등장하는 용어이다.
일단, 모두 "AWS의 서비스명"이다.
먼저, EKS는 AWS의 쿠버네티스 클러스터를 자동 운영해주는 서비스이다.
실제로 배포 자동화 등의 과정은 "쿠버네티스"가 관리한다.
로드 밸런싱으로는 Ingress, ALB(이것도 AWS 서비스다.. Application Load Balancer)가 가능하다.
이전에 '동적으로 늘어나는 트래픽에 따라 인스턴스와 컨테이너의 개수가 동적으로 늘어난다'고 설명한 부분에 이어서 설명하자면,
서버를 직접 다루지 않는 쿠버네티스를 대신해서 AWS가 서버(노드)관리 까지 자동화 해주는 것이다.
ECS는 아예 쿠버네티스를 대체할 수 있는 AWS 자체의 오케스트레이션 도구이다.
그냥 [K8s의 AWS 버전]이라고 생각하면 편하다.
5. 실제 CI/CD 파이프라인 Flow
깃허브, 도커, EC2, 쿠버네티스까지 개념이 어느정도 잡혔는데,
"GitLab" "GitLab Runner"는 또 뭐야?
5-2. GitLab과 GitLab Runner
먼저 쉽게 생각하면 이 정도로 이해해도 된다.
GitHub = GitLab
GitHub Actions = GitLab Runner
조금의 차이점을 말하자면,
GitHub는 소스 코드 관리에 집중된 서비스이며 기본적으로 클라우드 기반이다.
하지만, GitLab은 자체 호스팅(온프레미스 사용)이 가능하기 때문에 실제 실무 사내망에서 운영하는 경우가 많다.
(또한, GitLab은 CI/CD 기능까지 기본 제공한다.)
GitHub Actions는 GitHub에서 제공하는 실행환경을 사용하고,
GiLab Runner는 직접 설치해서 사용하는 것이다.
그래서 기업에서는 보안적인 이슈도 있고,
"사내망에서 운영 + CI/CD + Docker Registry"를 한 번에 지원하기 때문에 GitLab을 선호하는 것 같다.
5-3. CI/CD 전체적인 흐름
그렇다면, 이 모든 것을 사용하는 회사의 실무에서의 CI/CD 흐름은 어떻게 될까?
1. 개발자 수동 과정 - GitLab / GitHub
- 개발자가 GitLab에 코드를 푸시한다. (git push)
2. CI 과정 - GitLab Runner / GitHub Actions / Jenkins
- GitLab CI/CD가 실행된다.
- .gitlab-ci.yml 파일에 명시된 대로 코드 빌드 & 테스트를 자동으로 수행한다.
- dockerfile 혹은 Docker-compose로 도커 이미지를 생성한다. (docker build)
FROM openjdk:17
WORKDIR /app
COPY target/myapp.jar myapp.jar
CMD ["java", "-jar", "myapp.jar"]- Private Docker Registry (AWS ECR or GitLab Registry)로 이미지를 push 한다. (docker push)
3. CD 과정 - Kubernetes, ECS, ArgoCD
- 쿠버네티스(EKS) or ECS에 배포한다.
- 기존 컨테이너를 새로운 이미지로 업데이트 한다.
- ALB/NLB [로드벨런서] 등을 통해 새로운 버전을 적용한다.
5-4. 참고 : 소스코드 배포의 CI 과정 (컨테이너 X)
우리가 CI/CD 해본다고 처음에 소스코드 배포의 CI를 경험해본다.
.github/workflows/cicd.yml 에 다음과 같은 내용을 적는다.
1. 개발자 수동 과정
- 개발자가 main에 코드 푸시
2. CI 과정
- GitHub Actions 실행 [main에 push를 트리거로 설정]
- JDK 17 환경 설정 & Maven으로 빌드 (mvn clean package)
- 필요 시 테스트 수행
- 빌드된 myapp.jar 생성
3. CD 과정
- SSH 키 설정 (GitHub Secrets에서 EC2 정보 가져옴)
- EC2 서버로 빌드된 JAR 파일 전송 (scp)
- EC2에서 deploy.sh 실행
- 기존 실행 중인 myapp.jar 종료 (pkill -f 'java -jar' || true)
- 최신 JAR 실행 (nohup java -jar /home/ubuntu/myapp.jar > /home/ubuntu/myapp.log 2>&1 &)
여기서 K8s 없이 도커만 사용한다면,
deploy.sh 를 수정!
- 기존 컨테이너 종료
- 최신 Docker 이미지 Pull
- 새 컨테이너 실행 (docker run)
[cicd.yml]
name: CI/CD for Spring Boot (JAR)
on:
push:
branches:
- main # main 브랜치에 push될 때 실행
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v3
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
distribution: 'temurin'
java-version: '17'
- name: Build with Maven
run: mvn clean package
- name: Set up SSH key
run: |
mkdir -p ~/.ssh
echo "${{ secrets.EC2_SSH_KEY }}" > ~/.ssh/id_rsa
chmod 600 ~/.ssh/id_rsa
ssh-keyscan -H ${{ secrets.EC2_HOST }} >> ~/.ssh/known_hosts
- name: Transfer JAR to EC2
run: |
scp -i ~/.ssh/id_rsa target/myapp.jar ubuntu@${{ secrets.EC2_HOST }}:/home/ubuntu/myapp.jar
- name: Restart application on EC2
run: |
ssh -i ~/.ssh/id_rsa ubuntu@${{ secrets.EC2_HOST }} <<EOF
pkill -f 'java -jar' || true
nohup java -jar /home/ubuntu/myapp.jar > /home/ubuntu/myapp.log 2>&1 &
EOF
[deploy.sh]
#!/bin/bash
# 기존 실행 중인 JAR 프로세스 종료
pkill -f 'java -jar' || true
# 최신 JAR 실행
nohup java -jar /home/ubuntu/myapp.jar > /home/ubuntu/myapp.log 2>&1 &
+ 서비스의 분류 체계
✅ 컨테이너 오케스트레이션 도구
| 도구 | 역할 | 설명 |
| 쿠버네티스(Kubernetes) | 컨테이너 자동 운영 | 컨테이너를 배포, 확장, 복구 |
| EKS (AWS Elastic Kubernetes Service) | AWS에서 쿠버네티스를 관리 | AWS에서 쿠버네티스 클러스터를 자동 운영 |
| ECS (AWS Elastic Container Service) | AWS에서 컨테이너 관리 | AWS의 자체 컨테이너 오케스트레이션 서비스 (쿠버네티스 아님) |
➡ 즉, ECS는 AWS 독자적인 컨테이너 관리 서비스고, EKS는 AWS에서 쿠버네티스를 운영하는 서비스
✅ CI/CD 배포 자동화 도구
| 도구 | 역할 | 설명 |
| Jenkins | CI/CD 자동화 | 오픈소스 CI/CD 도구 (서버 필요) |
| GitLab CI/CD | CI/CD 자동화 | GitLab 내장 CI/CD |
| GitHub Actions | CI/CD 자동화 | GitHub 내장 CI/CD |
| AWS CodePipeline | AWS 전용 CI/CD | AWS에서 코드 → 배포 자동화 |
| ArgoCD | 쿠버네티스 전용 CD | GitOps 방식으로 쿠버네티스 배포 자동화 |
💡 즉, Jenkins/GitLab CI/CD/GitHub Actions는 어디든 배포 가능, CodePipeline은 AWS 전용, ArgoCD는 쿠버네티스 전용!
✅ 인프라 서비스 (서버/네트워크)
| 도구 | 역할 | 설명 |
| EC2 | 가상 서버 제공 | AWS에서 제공하는 가상 서버 (VM) |
| S3 | 객체 스토리지 | AWS에서 파일 저장 |
| AWS ECR | 컨테이너 이미지 저장소 | AWS에서 Docker 이미지 저장 |
💡 즉, EC2는 물리 서버 대여, ECR은 Docker Hub 같은 컨테이너 이미지 저장소 역할!
세부적인 설명에도 전체 그림이나 Flow 등이 머리 속에 들어오지 않아
시간을 내어 정리하는 시간을 가지고 싶었습니다.
저처럼 서버 개발은 해보았지만, 클라우드에 대해 입문 하시는 분들은 다음 글을 읽어보시면 도움이 되실 것 같습니다.
0. 들어가기 전
클라우드 과정을 짧은 기간에 공부하다 보니, 다음과 같은 질문들이 마구마구 지나가기 시작했다.
도커와 컨테이너의 정의가 정확히 어떻게 되지?
이미지와 컨테이너? 대충은 객체와 인스턴스 느낌인데 정확히 어떻게 돌아가는 거지?
도커를 사용하면 기존 EC2에 소스코드를 올리는 방식은 어떻게 다르지?
CI/CD 파이프라인의 정확한 동작 Flow는 어떻게 되는거지
젠킨스, 깃허브 액션 등 툴이 너무 많으니 분류 기준이 머리 속에 확립이 안된다..
왜 기업들은 사내망에서 GitLab을 더 많이 사용하는걸까?
허브? 레지스트리? 왜 이미지를 외부에 저장하는 과정이 필요하지?
EKS, ECS ? 실제 AWS에서 제공하는 컨테이너 관련 서비스는 어떻게 다루는거지?
쿠버네티스는 정확히 인프라인가? 어떠한 툴인가? 하나의 환경인가?
너무 많은 의문점들이 머리 속을 헤매기 시작했다.
먼저 대단원을 소개하면,
- 클라우드와 컨테이너 개념
- 컨테이너 기반 배포와 CI/CD에 관해
- 클라우드 네이티브 아키텍처와 AWS에 대해 연결해 이해해보자.
끝으로 쿠버네티스에 대한 개념을 연결해서 정리하면,
이후 클라우드 공부하는 데 머리 속에 큰 틀은 잡혀있을 것이다.
1. 클라우드 환경이라는 것이 정확히 어떤 의미인가?
1-1. 클라우드가 기존 온프레미스 환경과 어떻게 다른가?
결론부터 말하면, 클라우드란 "컴퓨터 자원을 더 유연하게 제공하는 방식" 이라고 이해하면 편하다.
먼저 전통적인 IT 인프라 방식과 비교하면 좋다.
클라우드가 등장한 이유
만약 자체적으로 온프레미스 환경으로 사내에서 직접 서버를 구축한다고 가정해보자.
- 데이터 센터에 서버를 구매하고 설치한다.
- 네트워크를 구축하고, 스토리지를 구성한다.
- 방화벽, 보안 규칙 등의 보안 설정을 한다.
- 장애가 발생하면 직접 노트북을 연결하여 CLI로 직접 장애 대응을 한다.
- 이후 끊임없는 유지 보수가 필요하다.
물론 규모가 작은 회사나, 클라우드 비용을 장기적으로 아끼고 싶다면 충분히 고려할 수 있는 옵션이지만
기본적으로 초기 비용이 비싸고, 유지 보수가 어려우며 확장성이 제한적 이라는 명확한 단점이 있다.
이럴 때 클라우드 제공업체에게 서버를 빌려쓰고 반납하는 개념을 "클라우드"라고 한다.
(가장 대표적인 제공업체는 AWS, Azure 등이 있다.)
클라우드에서는 클릭 몇 번으로 서버를 만들고, 필요하면 바로 확장할 수 있다.
즉, 비용과 유지보수 부담을 줄이면서, 유연하게 인프라를 운영할 수 있는 방식이라고 보면 된다.
1-2. 가상화
클라우드/ 컨테이너에 개념을 이해하려면 가상화만 이해하면 된다.
가상화
가장 중요한 개념은 "가상화"이다.
초반에 말했듯 과거에는 "물리 서버 1대 = 서비스 1개" 였고, 그에 따른 어려움이 있었다.
예를 들어 이런 상황을 생각해보자.
현재 본인의 컴퓨터에서 Java 17, MySQL 8.0 으로 서비스를 돌리고 있다.
그런데, 추가 서비스를 다른 부서가 만들었고, 그 서비스와 통합하려고한다.
애초에 계획되지 않은 통합이었기에, 해당 부서는 Java 11, MySQL 5.7 을 사용하고 있었고,
의존성 문제, 포트 충돌에 설정 관리에, 경로 문제까지 마구마구 문제가 터져나왔다...
마구마구 충돌~~~~~
그럼 그냥 이런 생각을 할 수 있다.
'아, 그냥 다른 환경에서 돌아갈 수 있도록 컴퓨터를 하나 더 사자!'
(단순한 해결책일 수록 돈이 많이 든다..)
그래서 내 컴퓨터 하나에 각각 다른 환경을 나누고 싶은 생각이 들었다.
(마치 내 컴퓨터 하나를 여러 개의 컴퓨터로 쪼개듯)
→ Host OS 위에 여러 개의 (가상 머신)VM을 띄우고, 버전에 맞는 각 OS 위에 앱들을 띄운다.
이것이 Hypervisor의 가상화 기술이다.
즉, [가상화]라는 것은
VM이나 이후에 나올 컨테이너 등에 대한 포괄적인 IT 개념이며,
물리적인 공간을 논리적으로 나눈다는 뜻이다.
(V-LAN도 마찬가지)
쉽게 한 층에 가벽을 세워서 공간을 나누는 모습을 생각하면 편하다.
사실 Virtual Box나 VM Ware 설치하고 우분투를 설치해본 분들이라면 무슨 느낌인지 바로 아실 것이다.
하지만 가상 머신은 격리/독립된 환경에서 각기 다른 앱들을 돌릴 수 있다는 장점이 있지만,
애뮬레이터, OS의 부팅 등 VM 환경은 상당히 무거웠고,
또한 어플리케이션의 확장에 한계가 있었다.
2. 컨테이너와 도커
2-1. 컨테이너
어플리케이션 하나 돌리려고, 가상 머신을 돌리는 것은 마치 이사할 때마다 가벽을 각각 짓는 것과 같다..
(그냥 방을 하나 더 짓는 격)
그래서 가상 머신 방식보다 더 가볍고 빠른 방식이 탄생한다.
그냥 "필요한 모든 것을 박스에 담아서 환경에 구애 받지 않도록 하면 되잖아"
컨테이너는 OS 자체를 가상화 하는게 아니라 Host OS 위에서 가벼운 프로세스 형태로 돌아가기 때문에 훨씬 빠르고 가볍다.
또한, 하나의 OS 위에서 여러 개의 어플리케이션을 독립적으로 실행시킬 수 있다.
이를 OS 수준에서 격리가 가능하기 때문에 서로 충돌 없이 동작 한다.
<참고로, 컨테이너는 원래 리눅스의 네임스페이스(namespaces)와 cgroups(control groups)라는 기술을 기반으로 프로세스를 격리하는 개념이다.>
즉, 우리가 빌린 EC2 서버에서 여러 개의 서비스를 컨테이너로 격리시켜 돌릴 수 있다는 것이다.
2-2. 도커
컨테이너의 개념은 사실 리눅스에서 예전부터 나온 개념이지만,
이를 실제 애플리케이션에 적용하고 실용화 시킨 것은 [Docker]이다.
기존에는 컨테이너 환경을 직접 설정해야 했지만,
도커는 명령어 몇 개 만으로 컨테이너 실행이 가능하도록 한다.
또한 도커를 이용해 컨테이너를 패키징하고, 배포하고, 실행하는 모든 과정을 자동화할 수 있다.
(Dockerfile 혹은 Docker-Compose)
오해하면 안되는 것이 "도커"가 "컨테이너" 자체는 아니다.
도커는 "컨테이너 기술에 여러 기능을 추가한 오픈소스 프로젝트"이다.
그렇다면 도커의 핵심 요소에서 이미지, 컨테이너, 허브는 정확히 어떤 의미일까..?
도커 이미지
- 실행 가능한 컨테이너를 만들기 위한 템플릿이다!
(붕어빵 틀)
도커 컨테이너
- 도커 이미지에서 실행된 어플리케이션이다!
(리얼 구워서 나온 붕어빵 실체)
=> 쉽게 말하면 "도커 이미지(Image)와 컨테이너(Container) 관계는 클래스(Class)와 인스턴스(Instance) 관계랑 똑같다!"
도커 허브 [레지스트리]
- 이미지를 공유할 수 있는 저장소이다.
=> 깃 허브랑 이름이 비슷하다.
맞다. 깃허브는 소스코드를 저장하는 저장소라면, 도커허브는 도커 이미지를 저장하는 저장소이다.
미리 Flow를 말해주자면,
GitHub에서 소스 코드 저장
-> 작성된 Dockerfile을 통해 소스코드를 기반으로 Docker 이미지 빌드
-> Docker Hub에 업로드
-> OS에서 다운로드 하여 실행
또한 "도커 허브"는 하나의 도커 레지스트리 라는 점을 알아 두자.
3. 도커 컨테이너 기반의 배포 방식
3-1. 기존 배포 방식 (EC2에 소스코드 직접 배포하기)
기존 방식은 EC2(가상 서버)를 대여한 뒤, 소스코드를 직접 올려 실행하는 방식이다.
서비스를 한 번이라도 올려봤다면 다들 익숙한 방법일 것이다.
- AWS에서 EC2 인스턴스 생성
- SSH로 EC2에 접속
- 필요 패키지 및 라이브러리 해당 EC2에 설치
- 소스코드 직접 올리기
- 실행 스크립트 작성
-> 서버 마다 다른 환경 때문에 다른 환경으로 옮길 때 문제가 잦다
배포할 때마다 환경 설정을 매번 다시 해야 한다.
확장이 어렵다 등의 단점이 있다.
그렇다면 컨테이너 기반의 배포 방식은 어떻게 다를까
3-2. 도커 컨테이너 기반 배포 방식 : Dockerfile
'컨테이너 기반 배포'라는 것은 EC2를 운영체제의 단위로 사용하는 것이 아니라, 컨테이너 단위로 격리하여 실행한다.
도커 컨테이너 자체가 앱이 실행되는 가벼운 가상 머신의 역할을 하기 때문이다.
CI/CD를 적용하지 않은 수동 배포 방식에 대해 먼저 알아보자.
1. Dockerfile 생성
- 컨테이너를 어떻게 만들어야 하는지를 설명하는 설명서 혹은 레시피 작성 => 결과물은 '이미지'가 나온다.
(이미지를 실행하면 컨테이너가 가동 된다고 했습니다.)
- 필요한 파일과 의존성이 명시되어 있고, 환경 변수 설정과 스크립트가 작성되어 있다.
- 명령어들이 layer 형태로, 순차적으로 실행되기 때문에 자주 변경되지 않는 파일부터 작성한다.
2. Image build
- Dockerfile을 이용해서 이미지를 만든다.
- 어플리케이션의 스냅샷 (이미지가 생성된 그 순간의 프로젝트의 상태를 의미)
- 어플리케이션을 실행하는데 필요한 모든 정보를 포함한다. (불변의 상태)
3. 이미지를 컨테이너 레지스트리에 push
컨테이너 레지스트리는 public, private로 나뉜다.
대표적인 public Registry에 Docker Hub가 있다고 했다.
Private Registry에는 AWS, Azure 등에서 제공하는 레지스트리 도 있다.
4. 이미지를 pull 받아서 컨테이너를 실행
- 이미지의 인스턴스
- 이미지를 통해서 컨테이너를 생성하고 고립된 환경(EC2 등의 빌린 가상 서버)에서 실행한다.
-> docker run 한 줄이면 배포 완료 가능!
서비스 - 컨테이너 - 가상 서버의 관계
나는 이 내용을 듣다가 두 가지 궁금증이 들었다.
- 서비스 규모가 작으면 한 컨테이너에 다 갖다 박아도 되나..?
- 만약에 각각 한 컨테이너로 나눈다면, 한 EC2에 올리나? 여러 EC2에 올리나?
먼저, One Process per Container 원칙에 맞게, 한 서비스는 한 컨테이너에 담는 것이 원칙이다.
확장이 불가능하며, 하나의 서비스가 죽으면 모두 꺼지기 때문이다.
(서비스 별 로그 / 장애 관리 등... 길게 설명하지 않겠다.)
허나 2번의 질문은 서비스 규모와 운영 방식에 따라 다르게 선택해도 된다고 생각한다.
단일 서비스이고, 작은 서비스라면 충분히 한 EC2에 여러 컨테이너를 올려도 괜찮다고 생각한다.
특히 "docker-compose up -d" 한 번으로 모든 서비스가 한 서버에서 동작할 수 있기 때문이다.
또한, 64기가 서버를 AWS에서 대여한다고 했을 때,
4기가 짜리 서비스, 1기가 짜리 레디스 서비스 등을 따로 돌리는 것이 오히려 가격적으로 손해이기 때문이다.
허나 트래픽이 많거나, MSA 구조에서는 컨테이너를 자동 분산하는 것을 추천한다.
<꼭 한 서버가 하나의 컨테이너가 아니더라도 서버를 나누어 분하 분산을 해준다.>
(이 때 AWS의 ECS, EKS(쿠버네티스) 등을 사용한다.)
하나의 EC2가 다운되더라도 전체 서비스가 죽지 않도록 하는 것이 중요하기 때문이다.
4. Docker? Docker-Compose? Kubernates?
도커와, 도커를 사용하여 배포하는 것은 대충 어떤식으로 이루어지는 알아 보았다.
도커는 개별 컨테이너를 만들고 실행하는 도구이라고 하였다.
허나, 도커만 사용하면 하나의 애플리케이션 컨테이너는 실행할 수 있지만, 여러 개의 컨테이너를 관리하기 어렵다.
4-1. Docker Compose
이를테면, 실제 웹 애플리케이션을 배포한다고 생각해보자.
웹 서버(Nginx) + DB(MySQL) + 캐시(Redis)가 필요할 수도 있고, 이 컨테이너들을 관리할 것인가?
도커 컴포즈는 여러 개의 컨테이너를 한 번에 실행하고 관리할 수 있는 도구이다.
컨테이너가 많아질수록 관리가 힘들어진다.
하나의 컨테이너를 어떻게 만들어야 하는지를 설명하는 설명서 혹은 레시피를 Dockerfile이라고 하였다.
docker-compose은 여러 개의 컨테이너를 정의하고 한 번에 실행할 수 있는 파일 이다.
[예시 : 웹서버 + DB]
version: "3"
services:
web:
image: nginx
ports:
- "8080:80"
db:
image: mysql
environment:
MYSQL_ROOT_PASSWORD: example
바로 위에서 나온 "docker-compose up -d"로 한 번에 모든 컨테이너를 실행할 수 있다.
그런데 이런 생각이 든다.
바로 위에서 트래픽이 매우 많거나, MSA 구조에서는 컨테이너를 자동 분산하는 것을 추천한다고 하였다.
(이 때 AWS의 ECS, EKS(쿠버네티스) 등을 사용한다.)
그런데, 이렇게 여러 서버에 여러 개의 컨테이너가 띄워져있는 환경이라면,
Docker-Compose 만으로는 여러 서버를 관리하기 어려울 것이다.
또한, 만약 분산 부하를 관리해주는 툴을 사용한다면, 저 수많은 컨테이너들은 이 서버 저 서버를 옮겨다닐 것이다.
그래서 등장한 것이 쿠버네티스 이다.
4-2. Kubernates (K8s)
쿠버네티스는 컨테이너를 대량으로 운영할 때 필요한 오케스트레이션(Orchestration) 도구이다.
확실히 필요한 이유는 [도커나 도커 컴포즈는 한 서버에서만 컨테이너를 관리할 수 있다]는 한계가 있기 때문이다.
동적으로 늘어나는 트래픽에 동적으로 늘어나는 인스턴스와 컨테이너의 개수를 개발자가 관리하는 것에는 한계가 있다.
이러한 오케스트레이션 도구는
여러 서버에 있는 여러 컨테이너들을 관리해주고,
서버 장애가 나도 자동으로 컨테이너를 재시작하고,
로드 밸런싱도 자동으로 처리하는 등의 역할을 한다.
그럼 '쿠버네티스'라는 것이 정확히 어떤 개념에 속하는 걸까?
(이런 분류 체계의 개념을 잡는 것이 처음에 너무 어려웠다..)
K8S는 IaaS인가? 인프라인가? 툴인가? 환경인가?
- 먼저, 쿠버네티스 자체로써 서버의 기능은 제공하고 있지 않기 때문에, Infa as a Service라고 보기는 어렵다.
- 인프라 자체가 아닌 "컨테이너를 관리하는 소프트웨어(툴)"이라고 볼 수 있다.
- 이전에 보았던, 여러 대의 서버<노드>들에 여러 컨테이너가 띄워져있는 것을 쿠버네티스 클러스터라고 하는데,
이 클러스터 자체는 일종의 '컨테이너 운영 환경'이라고 볼 수 있다.
우리는 SpringBoot를 배울 때 IoC라는 것을 배웠다.
제어의 역전은 기존의 개발 방식에서 개발자가 직접 제어 흐름을 제어하는 것이 아니라,
외부의 프레임워크나 라이브러리가 제어 흐름을 대신해주는 것으로 이해하고 있다.
점점 자동화와 개발자가 비즈니스 로직에만 집중할 수 있도록 해주는 툴이 발전중이다.
노드 (Node)
또 이런 의문점이 든다.
쿠버네티스에서 중요한 요소인 Node(노드) 는 서버인데, 서버의 기능이 없다?
- 쿠버네티스 자체는 서버를 생성하고 관리하는 기능은 아예 없다.
하지만, 이미 존재하는 노드 위에서 컨테이너를 띄우고 관리하는 역할을 하는 것이다.
즉, 마스터 노드, 워커 노드 에서 쓰이는 용어인 노드는
쿠버네티스가 컨테이너를 실행할 "작업 공간"을 제공하는 서버(EC2, VM, 물리 서버)이다.
클러스터 안에서 노드를 관리하는 것은 맞지만, 직접 생성하거나 운영하지 않는다.
그렇다면, 쿠버네티스가 노드와 상호작용 하는 것은 어떤 것이 있을까?
간단히만 알아보자.
- 노드가 추가되면 새로운 컨테이너를 배치
- 노드가 장애가 나면 컨테이너를 다른 노드로 옮김
- 트래픽 증가 시 노드에 새로운 컨테이너를 배포
ECS? EKS?
쿠버네티스와 함께 자주 등장하는 용어이다.
일단, 모두 "AWS의 서비스명"이다.
먼저, EKS는 AWS의 쿠버네티스 클러스터를 자동 운영해주는 서비스이다.
실제로 배포 자동화 등의 과정은 "쿠버네티스"가 관리한다.
로드 밸런싱으로는 Ingress, ALB(이것도 AWS 서비스다.. Application Load Balancer)가 가능하다.
이전에 '동적으로 늘어나는 트래픽에 따라 인스턴스와 컨테이너의 개수가 동적으로 늘어난다'고 설명한 부분에 이어서 설명하자면,
서버를 직접 다루지 않는 쿠버네티스를 대신해서 AWS가 서버(노드)관리 까지 자동화 해주는 것이다.
ECS는 아예 쿠버네티스를 대체할 수 있는 AWS 자체의 오케스트레이션 도구이다.
그냥 [K8s의 AWS 버전]이라고 생각하면 편하다.
5. 실제 CI/CD 파이프라인 Flow
깃허브, 도커, EC2, 쿠버네티스까지 개념이 어느정도 잡혔는데,
"GitLab" "GitLab Runner"는 또 뭐야?
5-2. GitLab과 GitLab Runner
먼저 쉽게 생각하면 이 정도로 이해해도 된다.
GitHub = GitLab
GitHub Actions = GitLab Runner
조금의 차이점을 말하자면,
GitHub는 소스 코드 관리에 집중된 서비스이며 기본적으로 클라우드 기반이다.
하지만, GitLab은 자체 호스팅(온프레미스 사용)이 가능하기 때문에 실제 실무 사내망에서 운영하는 경우가 많다.
(또한, GitLab은 CI/CD 기능까지 기본 제공한다.)
GitHub Actions는 GitHub에서 제공하는 실행환경을 사용하고,
GiLab Runner는 직접 설치해서 사용하는 것이다.
그래서 기업에서는 보안적인 이슈도 있고,
"사내망에서 운영 + CI/CD + Docker Registry"를 한 번에 지원하기 때문에 GitLab을 선호하는 것 같다.
5-3. CI/CD 전체적인 흐름
그렇다면, 이 모든 것을 사용하는 회사의 실무에서의 CI/CD 흐름은 어떻게 될까?
1. 개발자 수동 과정 - GitLab / GitHub
- 개발자가 GitLab에 코드를 푸시한다. (git push)
2. CI 과정 - GitLab Runner / GitHub Actions / Jenkins
- GitLab CI/CD가 실행된다.
- .gitlab-ci.yml 파일에 명시된 대로 코드 빌드 & 테스트를 자동으로 수행한다.
- dockerfile 혹은 Docker-compose로 도커 이미지를 생성한다. (docker build)
FROM openjdk:17
WORKDIR /app
COPY target/myapp.jar myapp.jar
CMD ["java", "-jar", "myapp.jar"]- Private Docker Registry (AWS ECR or GitLab Registry)로 이미지를 push 한다. (docker push)
3. CD 과정 - Kubernetes, ECS, ArgoCD
- 쿠버네티스(EKS) or ECS에 배포한다.
- 기존 컨테이너를 새로운 이미지로 업데이트 한다.
- ALB/NLB [로드벨런서] 등을 통해 새로운 버전을 적용한다.
5-4. 참고 : 소스코드 배포의 CI 과정 (컨테이너 X)
우리가 CI/CD 해본다고 처음에 소스코드 배포의 CI를 경험해본다.
.github/workflows/cicd.yml 에 다음과 같은 내용을 적는다.
1. 개발자 수동 과정
- 개발자가 main에 코드 푸시
2. CI 과정
- GitHub Actions 실행 [main에 push를 트리거로 설정]
- JDK 17 환경 설정 & Maven으로 빌드 (mvn clean package)
- 필요 시 테스트 수행
- 빌드된 myapp.jar 생성
3. CD 과정
- SSH 키 설정 (GitHub Secrets에서 EC2 정보 가져옴)
- EC2 서버로 빌드된 JAR 파일 전송 (scp)
- EC2에서 deploy.sh 실행
- 기존 실행 중인 myapp.jar 종료 (pkill -f 'java -jar' || true)
- 최신 JAR 실행 (nohup java -jar /home/ubuntu/myapp.jar > /home/ubuntu/myapp.log 2>&1 &)
여기서 K8s 없이 도커만 사용한다면,
deploy.sh 를 수정!
- 기존 컨테이너 종료
- 최신 Docker 이미지 Pull
- 새 컨테이너 실행 (docker run)
[cicd.yml]
name: CI/CD for Spring Boot (JAR)
on:
push:
branches:
- main # main 브랜치에 push될 때 실행
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v3
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
distribution: 'temurin'
java-version: '17'
- name: Build with Maven
run: mvn clean package
- name: Set up SSH key
run: |
mkdir -p ~/.ssh
echo "${{ secrets.EC2_SSH_KEY }}" > ~/.ssh/id_rsa
chmod 600 ~/.ssh/id_rsa
ssh-keyscan -H ${{ secrets.EC2_HOST }} >> ~/.ssh/known_hosts
- name: Transfer JAR to EC2
run: |
scp -i ~/.ssh/id_rsa target/myapp.jar ubuntu@${{ secrets.EC2_HOST }}:/home/ubuntu/myapp.jar
- name: Restart application on EC2
run: |
ssh -i ~/.ssh/id_rsa ubuntu@${{ secrets.EC2_HOST }} <<EOF
pkill -f 'java -jar' || true
nohup java -jar /home/ubuntu/myapp.jar > /home/ubuntu/myapp.log 2>&1 &
EOF
[deploy.sh]
#!/bin/bash
# 기존 실행 중인 JAR 프로세스 종료
pkill -f 'java -jar' || true
# 최신 JAR 실행
nohup java -jar /home/ubuntu/myapp.jar > /home/ubuntu/myapp.log 2>&1 &
+ 서비스의 분류 체계
✅ 컨테이너 오케스트레이션 도구
| 도구 | 역할 | 설명 |
| 쿠버네티스(Kubernetes) | 컨테이너 자동 운영 | 컨테이너를 배포, 확장, 복구 |
| EKS (AWS Elastic Kubernetes Service) | AWS에서 쿠버네티스를 관리 | AWS에서 쿠버네티스 클러스터를 자동 운영 |
| ECS (AWS Elastic Container Service) | AWS에서 컨테이너 관리 | AWS의 자체 컨테이너 오케스트레이션 서비스 (쿠버네티스 아님) |
➡ 즉, ECS는 AWS 독자적인 컨테이너 관리 서비스고, EKS는 AWS에서 쿠버네티스를 운영하는 서비스
✅ CI/CD 배포 자동화 도구
| 도구 | 역할 | 설명 |
| Jenkins | CI/CD 자동화 | 오픈소스 CI/CD 도구 (서버 필요) |
| GitLab CI/CD | CI/CD 자동화 | GitLab 내장 CI/CD |
| GitHub Actions | CI/CD 자동화 | GitHub 내장 CI/CD |
| AWS CodePipeline | AWS 전용 CI/CD | AWS에서 코드 → 배포 자동화 |
| ArgoCD | 쿠버네티스 전용 CD | GitOps 방식으로 쿠버네티스 배포 자동화 |
💡 즉, Jenkins/GitLab CI/CD/GitHub Actions는 어디든 배포 가능, CodePipeline은 AWS 전용, ArgoCD는 쿠버네티스 전용!
✅ 인프라 서비스 (서버/네트워크)
| 도구 | 역할 | 설명 |
| EC2 | 가상 서버 제공 | AWS에서 제공하는 가상 서버 (VM) |
| S3 | 객체 스토리지 | AWS에서 파일 저장 |
| AWS ECR | 컨테이너 이미지 저장소 | AWS에서 Docker 이미지 저장 |
💡 즉, EC2는 물리 서버 대여, ECR은 Docker Hub 같은 컨테이너 이미지 저장소 역할!