
-
0. 개요
-
1. 정적 할당 (Static Allocation)
-
1-1. 정적 객체(Static objects)
-
1-2. 상수 (Constant)
-
2. 스택 기반 할당 (Stack-Based Allocation)
-
2-1. 지역 변수 (Local veriables)
-
2-2. 재귀 (Recursion) / 스택기반 할당의 등장
-
2-3. 스택(Stack) 기반 할당
-
2-4. Frame의 구성요소
-
2-5. 스택의 관리
-
2-6. Stack Frame의 위치
-
2-7. 재귀가 없는 언어에서의 지역변수의 스택 할당
-
3. 힙 기반 할당 (Heap-Based Allocation)
-
3-1. Heap
-
3-2. 힙의 관리 전략
-
3-3. 힙 관리 알고리즘
-
3-4. Pool을 이용한 힙 관리 알고리즘
-
4. Garbage Collection
0. 개요
✍️ 이전 포스트에서 배웠던
✍️ Static objects, Stack objects, Heap objects 또 추가로 Garbbage Collection에 대해 차근차근 알아보자.
✍️ 이는 모두 메모리/저장공간 관리에 관한 내용이다.
1. 정적 할당 (Static Allocation)
정적 할당은 객체의 수명과 관련된 메모리 할당 메커니즘 중 하나이다.
이전에 말했던 3가지 방법 중 첫 번째를 소개해보려고 한다.

1-1. 정적 객체(Static objects)
쉽게 말해 Memory에서 Code & Data에 해당하는 부분이다.
(이와 반대로 Heap과 Stack은 모두 run time 혹은 compile time에 동적으로 변한다)
이에는 전역 변수(Global variables), 기계 코드로 구성된 명령어(Instruction), 정적 변수(Static Veriables) 등이 있다.
이러한 객체들은 프로그램이 실행될 때 이미 존재하며 프로그램이 종료될 때까지 살아있다.
전역 변수는 프로그램의 어디서든 접근 가능한 변수로, 정적 할당 메커니즘을 사용하여 프로그램이 시작될 때 메모리에 할당된다.
또한 숫자, 문자 형태의 상수(Constant Lterals) 도 이에 포함된다.
ex. A = B / 14.7 또는 printf("hello, world\n")
정적 객체와 정적 변수는 프로그램이 시작할 때 할당되어 런타임 중에 생성 및 파괴되지 않는다.
이러한 객체들은 메모리에 한 번 할당되고 사용 가능한 동안 계속 사용된다.
이러한 특성으로 인해 정적 할당은 프로그램의 효율성과 일관성을 유지하기 위해 중요하다.
1-2. 상수 (Constant)
많은 프로그래밍 언어에서 이름이 지정된 상수(named constant)는 컴파일 타임에 결정될 수 있는 값을 가져야 한다.
이는 명시적 상수(manifest constants) 또는 컴파일 타임 상수(compile-time constants)라고도 불린다.
이러한 명시적 상수는 항상 정적으로 할당될 수 있다.
즉, 메모리의 고정된 위치에 값이 저장된다.
심지어 이러한 상수가 재귀 서브루틴(recursive subroutine) 내에서 로컬 변수로 사용된다 하더라도,
다른 서브루틴 호출 간에 동일한 위치를 공유할 수 있다.
multiple instances can share the same location.
// 8 공유 가능
a = 8;
b = 8;이것은 컴파일 타임에 상수의 값이 이미 결정되어 있으므로 가능한 것이다.
C or Ada 와 같은 언어에서는 Constant는 초기화 시점 (elaboration time/initialization time) 이후에 변경할 수 없다.
// 읽기 전용 함수
이러한 초기화 시점 상수(elaboration-time constants)는 재귀 서브루틴 내에서 사용될 때, 스택에 할당되어야 한다.
C#에서는 컴파일 타임 상수와 초기화 시점 상수를 구별한다.
const(compilte time)및 readonly(elaboration time)을 구분한다.
2. 스택 기반 할당 (Stack-Based Allocation)
2-1. 지역 변수 (Local veriables)
지역 변수는 일반적으로 해당 서브루틴(함수)이 호출될 때 생성되며 서브루틴이 반환될 때 파괴(삭제)된다.
이런 종류의 변수 할당은 일반적으로 스택(stack) 메모리를 기반으로 한다.
예를 들어, 서브루틴이 반복적으로 호출된다면 각 호출 간에 서로 독립적인 로컬 변수가 생성되므로 서로의 값을 간섭하지 않는다.
하나의 호출에서 생성된 로컬 변수는 그 호출에서만 존재하며 해당 호출이 완료될 때 파괴된다.
이것은 각 호출 간에 변수 값을 유지하고 서로 영향을 미치지 않도록 하는 중요한 특성이다.
이로써 각기 다른 서브루틴에서 같은 값의 로컬 변수를 사용할 수 있는 것이다.
- 재귀호출의 개념에서 각 instance들이 stack에 쌓이는 것을 생각하면 편하다.
호출되는 서브루틴이나 함수마다 로컬 변수가 생성 및 소멸되는 작업은 런타임(runtime)에 관리되어야 한다.
이것이 스택 메모리 기반의 로컬 변수 할당 방식의 동작 원리이다.
2-2. 재귀 (Recursion) / 스택기반 할당의 등장
Fortran는 초기 버전에서 재귀(Recursion)를 지원하지 않았다.
옛 버전의 Fortran 프로그램에서는 하나의 서브루틴(Subroutine) 호출만 활성화될 수 있었다.
이것은 곧 '재귀 호출을 허용하지 않았다'는 의미와 같다.
따라서 예전 Fortran에서는 서브루틴을 재귀적으로 호출할 수 없었다.
그러나 이후 Fortran는 로컬 변수를 정적 할당(static allocation)으로 관리하여
서로 다른 서브루틴 호출 간에 동일한 메모리 위치를 공유할 수 있도록 조치했다.
요약하면, 예전 Fortran에서는 재귀 호출이 지원되지 않지만, 일부 컴파일러는 정적 할당을 통해 이를 극복할 수 있었다.
2-3. 스택(Stack) 기반 할당
재귀(Recursion) 허용
<이러한 경우 로컬 변수의 정적 할당(static allocation)은 불가능>
실행 중 각 서브루틴 인스턴스마다 스택 내에 Frame(activation record)이 존재한다.
2-4. Frame의 구성요소
- Arguments to called routines : 호출된 subroutine에 들어온 인자값들
- Temporaries : 복잡한 계산을 위한 임시 값, 중간 결과를 보관
- Local variables : 지역변수
- Miscellaneous bookkeeping : (bookkeeping information 통해 이전 프레임으로 복귀하는 용도(재귀))
-> 이를 통해 재귀 서브루틴이 제대로 작동할 수 있도록 함.

현재 코드 상황에 따라 오른쪽 수식과 같이 아래에서부터 올라가면서 Subroutine이 진행된다.
이는 실시간으로 각 서브루틴마다 기록되는 것이 다르며, 실행 상황에 따라 변경된다 -> Activation Record
이를 테면 if / else 등의 상황에 따라 변경될 수 있는 것.
2-5. 스택의 관리
호출 시퀀스와 서브루틴 자체의 서브루틴 프롤로그 및 에필로그에 의해 유지되고 관리된다.
호출 시퀀스: caller에 의해 호출 전후에 실행되는 코드
프롤로그: 호출된 서브루틴의 시작 부분에서 실행되는 코드 : 스택 설정
에필로그: 호출된 서브루틴의 끝에서 실행되는 코드 : 스택 정리
-> 스택관리는 함수 첫 부분과 끝 부분에서 이루어진다.
2-6. Stack Frame의 위치
compile 시점에서 stack frame의 위치는 예측할 수 없다. -> 코드가 돌아가봐야 알 수 있다?
Why? Activation Record
하지만, 각 frame 내부의 objects들의 offset은 정적으로 결정되기 때문에 예측가능하다.
이것은 주로 스택이 "하향식"으로 낮은 메모리 주소 방향으로 확장하기 때문.
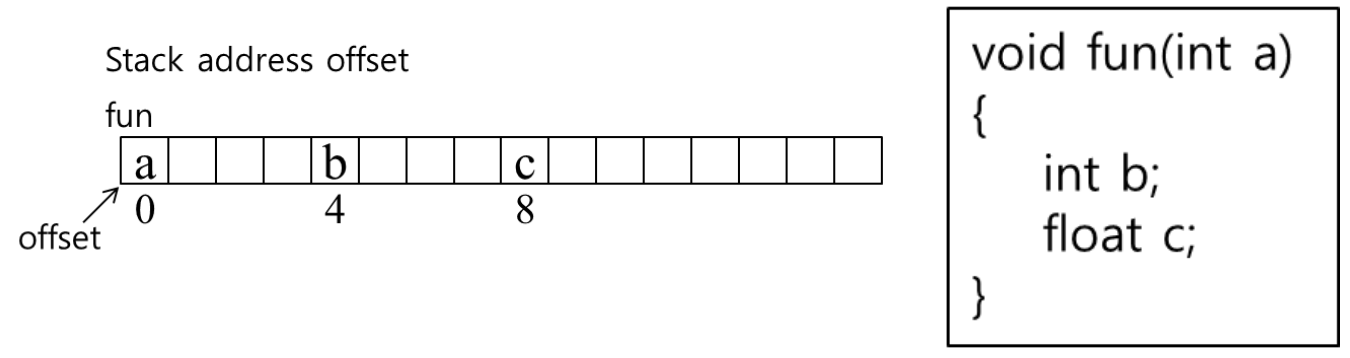
2-7. 재귀가 없는 언어에서의 지역변수의 스택 할당
🤔 그렇다면, 재귀가 없는 언어에서는 동적으로 할당하는 것의 이점이 없을까?
NO. 분명히 이점이 있다.
호출 중에 다양한 서브루틴이 동시에 실행되는 경우에도 각 서브루틴의 로컬 변수에 대한 메모리를 효율적으로 관리할 수 있다.
이로써 프로그램의 유연성이 향상되고 메모리 효율성도 높아질 수 있다.
3. 힙 기반 할당 (Heap-Based Allocation)
3-1. Heap
힙(Heap)은 저장 영역의 한 부분으로, 임의의 시간에 하위 블록을 할당 및 해제될 수 있는 공간이다.
-> 동적 할당 공간
Heap은 동적으로 할당되는 자료 구조 및 일반적인 문자열에 필요하다.
(문자열은 상황에 따라 크기가 달라지기 때문)
3-2. 힙의 관리 전략
힙의 공간을 관리하기 위해 여러 전략이 사용될 수 있다.
중요한 것은 속도와 공간이다.
1. 내부 단편화(Internal Fragmentation)
해당 객체를 보관하는 데 필요한 것보다 큰 블록을 할당하는 경우.
추가 공간이 사용되지 않고 낭비되는 것.

2. 외부 단편화(External Fragmentation)
힙에서 블록들이 연속적으로 위치하지 않고, 작은 조각들로 나뉘어 있는 경우. (동적 할당인 상황에서 발생한다.)
이로 인해 새로운 블록을 할당하는 데 어려움이 발생할 수 있고, 메모리 공간의 효율성이 떨어질 수 있다.
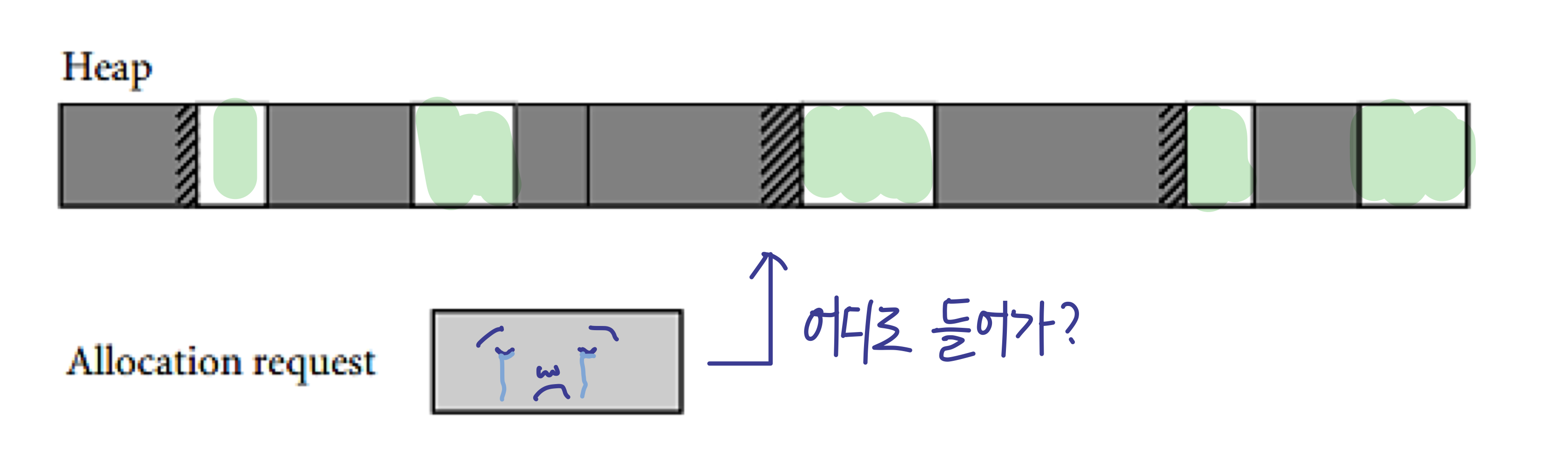
3-3. 힙 관리 알고리즘
- the free list : free 공간의 block 들이 linked list 형태로 이어놓은 것
이후 새로 객체를 할당할 때 이 linked list를 검색한다.
이러한 상태에서, 빈 공간을 검색할 때 다양한 알고리즘이 사용될 수 있다.
1. First-fit : 들어갈수 있는 첫 번째 free 블록 선택 (최고 속도)
2. Best-fit : 들어갈 수 있는 가장 작은 free 블록 선택 (최고 효율 / 속도는 감소)
(사실 어떤 알고리즘을 쓰던 오래 쓰다 보면 성능은 비슷하다고 한다.)
- free block이 너~무 크거나 너~무 작으면 이러한 알고리즘을 사용할 수도 있다.
- 필요 이상으로 크면, blcok을 둘로 나누고 안쓰는 부분을 자유 리스트로 반환한다.
- 매우 작은 공간이라면 free list에 추가하지 않는다.
블록 할당 해제되고 free list로 돌아갈 때, 물리적으로 인접한 블록을 검사하여 결합한다.
(c언어의 malloc, free, new 등 호출시 실행하는 행위와 비슷하다)
3-4. Pool을 이용한 힙 관리 알고리즘
위와 같은 방식으로 알고리즘을 꾸린다면,
단일 free list를 가지고 있는 알고리즘은 할당에 O(n)의 비용이 할당된다.
이 비용을 줄이기 위해 각기 다른 size의 block을 분류화 하여 관리할 수도 있다.
ex. 객체크기 6은 [4, 8, 12...] 여러 그룹의 free list 그룹 중 '8 free list'에서 관리한다.
이 그룹을 "pool" 이라고 한다.
1. buddy system : 메모리 2의 거듭제곱 크기 기준으로 할당한다.
2. Fibonacci heap : 피보나치 수 기준으로 할당
- 아무리 제대로 반환이 된다고 하더라도, 불가피하게 작은 공간들이 남을 수밖에 없다. (External fregmentation)
-> Compact (압축) 으로 해결할 수 있다.
<하지만, 메모리 주소 값을 일일이 모두 변경해줘야 하는 너무 복잡한(expensive) 동작이다.>
... 이렇게 block의 reference를 모두 update 해주는 과정은 Garbage Collection에서도 나온다
4. Garbage Collection
Heap 기반 객체 할당은 특정 상황에서 유발한다.
- 객체의 인스턴트화
- list 끝에 append (추가)
- 이전의 짧은 문자열에 더 긴 값을 할당
많은 프로그래밍 언어에서는 객체가 어떤 프로그램 변수에서도 더 이상 접근할 수 없을 때 암묵적으로 해제(deallocated)되어야 한다.
// 더 이상 필요 없는 객체가 메모리를 잡아먹고 있으면 손해
이것은 Garbage Collection 메커니즘을 제공하여
이러한 도달할 수 없는(unreachable) 객체를 식별하고 회수(reclaim)해야 함을 의미한다.
할당-해제에는 2가지 방법이 있다.
명시적 할당-해제 / 암시적 할당-해제
대부분에 언어에서는 자동으로 할당 해제가 되지만, 몇몇 특정 언어(C, C++ 등)에서는 할당 해제에 명시가 필요하다.
1. Explicit deallocation (명시적 할당-해제)의 장단점
- 장점 : 간단한 구현, 빠른 실행 속도
- 단점 : 수동 할당 해제로 인한 여러 에러와 비용 문제.
- - 너무 빠른 해제 (사용 중인데 해제) : dangling reference
- - lifetime이 끝났는데도 해제하지 않음 : memory leak
2. Garbage Collection (암시적 할당-해제 의 장단점)
- 장점 : 수동 할당 해제할 필요 없음, 알고리즘의 바렂ㄴ으로 오버헤드 거의 x, 복잡해지고 규모가 커지는 현재 프로그램에서의 자동화
- 단점 : 구현 자체의 어려움.
- 그럼에도 Garbage Collection을 현대 많은 언어들이 사용하는 이유 (경향)
- 알고리즘의 개선
- 언어 구현의 복잡성 증가
- 선두 응용 프로그램의 증가
0. 개요
✍️ 이전 포스트에서 배웠던
✍️ Static objects, Stack objects, Heap objects 또 추가로 Garbbage Collection에 대해 차근차근 알아보자.
✍️ 이는 모두 메모리/저장공간 관리에 관한 내용이다.
1. 정적 할당 (Static Allocation)
정적 할당은 객체의 수명과 관련된 메모리 할당 메커니즘 중 하나이다.
이전에 말했던 3가지 방법 중 첫 번째를 소개해보려고 한다.
1-1. 정적 객체(Static objects)
쉽게 말해 Memory에서 Code & Data에 해당하는 부분이다.
(이와 반대로 Heap과 Stack은 모두 run time 혹은 compile time에 동적으로 변한다)
이에는 전역 변수(Global variables), 기계 코드로 구성된 명령어(Instruction), 정적 변수(Static Veriables) 등이 있다.
이러한 객체들은 프로그램이 실행될 때 이미 존재하며 프로그램이 종료될 때까지 살아있다.
전역 변수는 프로그램의 어디서든 접근 가능한 변수로, 정적 할당 메커니즘을 사용하여 프로그램이 시작될 때 메모리에 할당된다.
또한 숫자, 문자 형태의 상수(Constant Lterals) 도 이에 포함된다.
ex. A = B / 14.7 또는 printf("hello, world\n")
정적 객체와 정적 변수는 프로그램이 시작할 때 할당되어 런타임 중에 생성 및 파괴되지 않는다.
이러한 객체들은 메모리에 한 번 할당되고 사용 가능한 동안 계속 사용된다.
이러한 특성으로 인해 정적 할당은 프로그램의 효율성과 일관성을 유지하기 위해 중요하다.
1-2. 상수 (Constant)
많은 프로그래밍 언어에서 이름이 지정된 상수(named constant)는 컴파일 타임에 결정될 수 있는 값을 가져야 한다.
이는 명시적 상수(manifest constants) 또는 컴파일 타임 상수(compile-time constants)라고도 불린다.
이러한 명시적 상수는 항상 정적으로 할당될 수 있다.
즉, 메모리의 고정된 위치에 값이 저장된다.
심지어 이러한 상수가 재귀 서브루틴(recursive subroutine) 내에서 로컬 변수로 사용된다 하더라도,
다른 서브루틴 호출 간에 동일한 위치를 공유할 수 있다.
multiple instances can share the same location.
// 8 공유 가능
a = 8;
b = 8;이것은 컴파일 타임에 상수의 값이 이미 결정되어 있으므로 가능한 것이다.
C or Ada 와 같은 언어에서는 Constant는 초기화 시점 (elaboration time/initialization time) 이후에 변경할 수 없다.
// 읽기 전용 함수
이러한 초기화 시점 상수(elaboration-time constants)는 재귀 서브루틴 내에서 사용될 때, 스택에 할당되어야 한다.
C#에서는 컴파일 타임 상수와 초기화 시점 상수를 구별한다.
const(compilte time)및 readonly(elaboration time)을 구분한다.
2. 스택 기반 할당 (Stack-Based Allocation)
2-1. 지역 변수 (Local veriables)
지역 변수는 일반적으로 해당 서브루틴(함수)이 호출될 때 생성되며 서브루틴이 반환될 때 파괴(삭제)된다.
이런 종류의 변수 할당은 일반적으로 스택(stack) 메모리를 기반으로 한다.
예를 들어, 서브루틴이 반복적으로 호출된다면 각 호출 간에 서로 독립적인 로컬 변수가 생성되므로 서로의 값을 간섭하지 않는다.
하나의 호출에서 생성된 로컬 변수는 그 호출에서만 존재하며 해당 호출이 완료될 때 파괴된다.
이것은 각 호출 간에 변수 값을 유지하고 서로 영향을 미치지 않도록 하는 중요한 특성이다.
이로써 각기 다른 서브루틴에서 같은 값의 로컬 변수를 사용할 수 있는 것이다.
- 재귀호출의 개념에서 각 instance들이 stack에 쌓이는 것을 생각하면 편하다.
호출되는 서브루틴이나 함수마다 로컬 변수가 생성 및 소멸되는 작업은 런타임(runtime)에 관리되어야 한다.
이것이 스택 메모리 기반의 로컬 변수 할당 방식의 동작 원리이다.
2-2. 재귀 (Recursion) / 스택기반 할당의 등장
Fortran는 초기 버전에서 재귀(Recursion)를 지원하지 않았다.
옛 버전의 Fortran 프로그램에서는 하나의 서브루틴(Subroutine) 호출만 활성화될 수 있었다.
이것은 곧 '재귀 호출을 허용하지 않았다'는 의미와 같다.
따라서 예전 Fortran에서는 서브루틴을 재귀적으로 호출할 수 없었다.
그러나 이후 Fortran는 로컬 변수를 정적 할당(static allocation)으로 관리하여
서로 다른 서브루틴 호출 간에 동일한 메모리 위치를 공유할 수 있도록 조치했다.
요약하면, 예전 Fortran에서는 재귀 호출이 지원되지 않지만, 일부 컴파일러는 정적 할당을 통해 이를 극복할 수 있었다.
2-3. 스택(Stack) 기반 할당
재귀(Recursion) 허용
<이러한 경우 로컬 변수의 정적 할당(static allocation)은 불가능>
실행 중 각 서브루틴 인스턴스마다 스택 내에 Frame(activation record)이 존재한다.
2-4. Frame의 구성요소
- Arguments to called routines : 호출된 subroutine에 들어온 인자값들
- Temporaries : 복잡한 계산을 위한 임시 값, 중간 결과를 보관
- Local variables : 지역변수
- Miscellaneous bookkeeping : (bookkeeping information 통해 이전 프레임으로 복귀하는 용도(재귀))
-> 이를 통해 재귀 서브루틴이 제대로 작동할 수 있도록 함.
현재 코드 상황에 따라 오른쪽 수식과 같이 아래에서부터 올라가면서 Subroutine이 진행된다.
이는 실시간으로 각 서브루틴마다 기록되는 것이 다르며, 실행 상황에 따라 변경된다 -> Activation Record
이를 테면 if / else 등의 상황에 따라 변경될 수 있는 것.
2-5. 스택의 관리
호출 시퀀스와 서브루틴 자체의 서브루틴 프롤로그 및 에필로그에 의해 유지되고 관리된다.
호출 시퀀스: caller에 의해 호출 전후에 실행되는 코드
프롤로그: 호출된 서브루틴의 시작 부분에서 실행되는 코드 : 스택 설정
에필로그: 호출된 서브루틴의 끝에서 실행되는 코드 : 스택 정리
-> 스택관리는 함수 첫 부분과 끝 부분에서 이루어진다.
2-6. Stack Frame의 위치
compile 시점에서 stack frame의 위치는 예측할 수 없다. -> 코드가 돌아가봐야 알 수 있다?
Why? Activation Record
하지만, 각 frame 내부의 objects들의 offset은 정적으로 결정되기 때문에 예측가능하다.
이것은 주로 스택이 "하향식"으로 낮은 메모리 주소 방향으로 확장하기 때문.
2-7. 재귀가 없는 언어에서의 지역변수의 스택 할당
🤔 그렇다면, 재귀가 없는 언어에서는 동적으로 할당하는 것의 이점이 없을까?
NO. 분명히 이점이 있다.
호출 중에 다양한 서브루틴이 동시에 실행되는 경우에도 각 서브루틴의 로컬 변수에 대한 메모리를 효율적으로 관리할 수 있다.
이로써 프로그램의 유연성이 향상되고 메모리 효율성도 높아질 수 있다.
3. 힙 기반 할당 (Heap-Based Allocation)
3-1. Heap
힙(Heap)은 저장 영역의 한 부분으로, 임의의 시간에 하위 블록을 할당 및 해제될 수 있는 공간이다.
-> 동적 할당 공간
Heap은 동적으로 할당되는 자료 구조 및 일반적인 문자열에 필요하다.
(문자열은 상황에 따라 크기가 달라지기 때문)
3-2. 힙의 관리 전략
힙의 공간을 관리하기 위해 여러 전략이 사용될 수 있다.
중요한 것은 속도와 공간이다.
1. 내부 단편화(Internal Fragmentation)
해당 객체를 보관하는 데 필요한 것보다 큰 블록을 할당하는 경우.
추가 공간이 사용되지 않고 낭비되는 것.
2. 외부 단편화(External Fragmentation)
힙에서 블록들이 연속적으로 위치하지 않고, 작은 조각들로 나뉘어 있는 경우. (동적 할당인 상황에서 발생한다.)
이로 인해 새로운 블록을 할당하는 데 어려움이 발생할 수 있고, 메모리 공간의 효율성이 떨어질 수 있다.
3-3. 힙 관리 알고리즘
- the free list : free 공간의 block 들이 linked list 형태로 이어놓은 것
이후 새로 객체를 할당할 때 이 linked list를 검색한다.
이러한 상태에서, 빈 공간을 검색할 때 다양한 알고리즘이 사용될 수 있다.
1. First-fit : 들어갈수 있는 첫 번째 free 블록 선택 (최고 속도)
2. Best-fit : 들어갈 수 있는 가장 작은 free 블록 선택 (최고 효율 / 속도는 감소)
(사실 어떤 알고리즘을 쓰던 오래 쓰다 보면 성능은 비슷하다고 한다.)
- free block이 너~무 크거나 너~무 작으면 이러한 알고리즘을 사용할 수도 있다.
- 필요 이상으로 크면, blcok을 둘로 나누고 안쓰는 부분을 자유 리스트로 반환한다.
- 매우 작은 공간이라면 free list에 추가하지 않는다.
블록 할당 해제되고 free list로 돌아갈 때, 물리적으로 인접한 블록을 검사하여 결합한다.
(c언어의 malloc, free, new 등 호출시 실행하는 행위와 비슷하다)
3-4. Pool을 이용한 힙 관리 알고리즘
위와 같은 방식으로 알고리즘을 꾸린다면,
단일 free list를 가지고 있는 알고리즘은 할당에 O(n)의 비용이 할당된다.
이 비용을 줄이기 위해 각기 다른 size의 block을 분류화 하여 관리할 수도 있다.
ex. 객체크기 6은 [4, 8, 12...] 여러 그룹의 free list 그룹 중 '8 free list'에서 관리한다.
이 그룹을 "pool" 이라고 한다.
1. buddy system : 메모리 2의 거듭제곱 크기 기준으로 할당한다.
2. Fibonacci heap : 피보나치 수 기준으로 할당
- 아무리 제대로 반환이 된다고 하더라도, 불가피하게 작은 공간들이 남을 수밖에 없다. (External fregmentation)
-> Compact (압축) 으로 해결할 수 있다.
<하지만, 메모리 주소 값을 일일이 모두 변경해줘야 하는 너무 복잡한(expensive) 동작이다.>
... 이렇게 block의 reference를 모두 update 해주는 과정은 Garbage Collection에서도 나온다
4. Garbage Collection
Heap 기반 객체 할당은 특정 상황에서 유발한다.
- 객체의 인스턴트화
- list 끝에 append (추가)
- 이전의 짧은 문자열에 더 긴 값을 할당
많은 프로그래밍 언어에서는 객체가 어떤 프로그램 변수에서도 더 이상 접근할 수 없을 때 암묵적으로 해제(deallocated)되어야 한다.
// 더 이상 필요 없는 객체가 메모리를 잡아먹고 있으면 손해
이것은 Garbage Collection 메커니즘을 제공하여
이러한 도달할 수 없는(unreachable) 객체를 식별하고 회수(reclaim)해야 함을 의미한다.
할당-해제에는 2가지 방법이 있다.
명시적 할당-해제 / 암시적 할당-해제
대부분에 언어에서는 자동으로 할당 해제가 되지만, 몇몇 특정 언어(C, C++ 등)에서는 할당 해제에 명시가 필요하다.
1. Explicit deallocation (명시적 할당-해제)의 장단점
- 장점 : 간단한 구현, 빠른 실행 속도
- 단점 : 수동 할당 해제로 인한 여러 에러와 비용 문제.
- - 너무 빠른 해제 (사용 중인데 해제) : dangling reference
- - lifetime이 끝났는데도 해제하지 않음 : memory leak
2. Garbage Collection (암시적 할당-해제 의 장단점)
- 장점 : 수동 할당 해제할 필요 없음, 알고리즘의 바렂ㄴ으로 오버헤드 거의 x, 복잡해지고 규모가 커지는 현재 프로그램에서의 자동화
- 단점 : 구현 자체의 어려움.
- 그럼에도 Garbage Collection을 현대 많은 언어들이 사용하는 이유 (경향)
- 알고리즘의 개선
- 언어 구현의 복잡성 증가
- 선두 응용 프로그램의 증가