
목차
-
0. Kubernetes 개요
-
쿠버네티스란?
-
1. 쿠버네티스 컴포넌트
-
1-1. K8s Cluster
-
1-2. K8s Cluster를 구성하는 코어 프로세스들
-
2. 쿠버네티스 API
-
3. 쿠버네티스 아키텍처
-
3-1. 컨테이너 (Container)
-
3-2. 노드 (Node)
-
4. 오브젝트
-
4-1. K8s Object
-
4-2. Object 기술
-
5. 워크로드
-
6. 워크로드 : 파드 (Pod)
-
6-1. 파드 (Pod) = 실제 실행 단위
-
6-2. 파드 실행을 위한 필수 구성 요소
-
6-3. 파드의 기본 개념
-
6-4. 파드와 Manifast
-
6-5. 파드 생성 및 관리
-
6-6. 파드 배치
-
7. 워크로드 : 워크로드 리소
-
7-1. 컨트롤러 (Controller)
-
컨트롤러
-
7-2. 디플로이먼트
-
7-3. 리플리카셋
-
7-4. 잡
-
7-5. Cron Job
-
8. 워크로드 응용
-
8-1. 초기화 전용 컨테이너 (Init Container)
-
8-2. Pod의 Health Check 기능
-
8-3. 사이드카 패턴 - Dockerfile
-
8-4. 애플리케이션 버전 변경 전략
-
9. 서비스
-
9-1. 서비스
-
9-2. 부하분산과 어피니티
-
10. 서비스 종류 ; 클러스터 네트워킹
-
10-1. ClusterIP (Default) : 클러스터 내부 전용
-
10-2. NodePort : 클러스터 내부 + 외부
-
10-3. LoadBalancer : 클러스터 내부 + 외부 (대표 IP 제공)
-
10-4. ExternalName : 외부 서비스 연결
-
10-5. 서비스와 파드의 연결
-
11. 인그레스 (Ingress) : 외부와 서비스 간 통신
-
11-1. 공개 URL과 애플리케이션 매핑
-
11-2. 모더니제이션과 세션 어피니티(Session Affinity)
-
11-3. HPA 설정
-
12. 로드밸런싱
-
13. 스토리지
-
13-1. 스토리지
-
13-2. 스토리지 사용 방식 비교
반응형
0. Kubernetes 개요

쿠버네티스란?
- 컨테이너화된 애플리케이션을 자동으로 배포하고 관리하는 오케스트레이션 도구
- 도커는 컨테이너화해서 이미지를 만드는 것이라고 했다.
- 쿠버네티스는 컨테이너가 실행될 환경을 만들고, 이를 효과적으로 관리하는 역할을 한다.
- 즉, “컨테이너의 실행/관리/운영 환경”을 제공하는 것
1. 쿠버네티스 컴포넌트
1-1. K8s Cluster
- 쿠버네티스를 배포하면 Cluster를 얻는다.
- 쿠버네티스 클러스터 = 하나의 실행 환경(Infrastructure Environment)

- K8s 클러스터는 최소 한 개의 Worker Node를 가진다.
- Node는 쉽게 말해 ‘서버’라고 생각하면 편하다.
- Worker Node는 애플리케이션을 구성하는 Pod를 실행하는 역할을 한다.
- 미리 설명하자면, 하나의 Pod는 여러 개의 컨테이너로 구성될 수 있으며,
- 이 Pod가 바로 K8s의 최소 실행 단위이다.
- 다만, K8s가 제대로 동작하기 위해서는 내부적으로 다양한 코어 프로세스(컴포넌트)가 필요하다.
1-2. K8s Cluster를 구성하는 코어 프로세스들
- K8s 클러스터를 “소프트웨어 구성” 관점으로도 구분할 수 있다.
- Control Plane Components와 Node Componets로 구성된다.
- Control Plane Components = 마스터 노드에서 실행되는 관리 프로세스들
- Node Componets = 워커 노드에서 실행되는 실행 프로세스들
Control Plane Componets
- 클러스터의 상태를 조정하고 관리하는 역할을 한다.
- 보통 마스터 노드에서 실행된다.
- 참고 : 고가용성 클러스터 환경에서는 여러 노드에 분산될 수도 있다.
| 구성 요소 | 역할 |
|---|---|
| kube-apiserver | API 요청을 처리하고 클러스터 상태를 관리 |
| etcd | 클러스터의 모든 상태 데이터를 저장하는 분산 키-값 저장소 |
| kube-scheduler | 새로운 파드를 실행할 최적의 노드를 선택 |
| kube-controller-manager | 노드, 파드, 레플리카 관리 등 다양한 컨트롤러 실행 |
| cloud-controller-manager | 클라우드 서비스(AWS, GCP 등)와 연계 |
Node Componets
- 컨테이너(Pod)를 실행하고 네트워크를 관리하는 역할을 한다.
- 워커 노드에서 실행된다.
| 컴포넌트 | 역할 |
|---|---|
| kubelet | 각 노드에서 파드 실행 및 상태 관리 |
| kube-proxy | 네트워크 트래픽 라우팅 및 로드 밸런싱 수행 |
| 컨테이너 런타임 (containerd, Docker) | 컨테이너 실행 엔진 |
| CNI 플러그인(Flannel, Calico 등) | 노드 간 네트워크 연결 |
참고 : 에드온
- 코어(핵심) 프로세스는 아니지만, 기본적으로 제공하는 컴포넌트 들도 있다.
- 기본 기능을 확장하는 추가 컴포넌트들이다.
- Kubernetes Dashboard
- 웹 UI 기반의 클러스터 관리 도구이다.
- CLI에서는 kubectl 명령어로 Api를 보냈다.
- 웹 UI 기반의 클러스터 관리 도구이다.
2. 쿠버네티스 API
- 쿠버네티스 조작은 모두 API로 동작한다.
- 우리가 CLI에서 kubectl 명령어로 보내는 모든 작업들은 마스터 노드 내부의 “API Server(kube-apiserver)”에 도착한다.
- API Server가 "쿠버네티스의 중앙 게이트웨이" 역할을 하면서 모든 요청을 받아서 처리하는 구조이다.
- 알아서 적절한 컴포넌트로 요청이 전달!
- K8s Dashboard (웹 UI), 직접 API 호출, Terraform (내부적으로 kube-apiserver API 호출) 등으로도 호출할 수 있지만,
- 어떤 방법으로든 쿠버네티스를 조작하든, 결국 API 요청이 kube-apiserver로 전달된다.

3. 쿠버네티스 아키텍처
3-1. 컨테이너 (Container)
Container에 대한 용어를 잠시 짚고 넘어가보자.
- 그냥 Docker Container 로 이해하면 된다.

- 실제 애플리케이션이 실행되는 환경
- 다만, 단독으로 존재하지 않고 반드시 "파드(Pod)" 내부에서 실행된다!
- 단독 실행은 불가능 (K8s는 컨테이너 실행 도구가 아니다!!!)
3-2. 노드 (Node)
- 컨테이너(Pod)를 실행하는 단위가 되는 머신(서버)이다.
- 노드는 물리 서버일 수도 있고, 가상 머신(VM)일 수도 있다.
- 이후 클라우드 환경에서 K8s를 다루는 것을 배울 예정이므로 쉽게 ‘EC2 = Node’ 라고 생각해도 된다.

- K8s 클러스터를 “물리적인 구성” 관점에서 노드 별로 구분할 수 있다.
- 기능별로 “마스터 노드”와 “워커 노드”로 구분된다.
- 보통 1개 이상의 마스터 노드 + 여러 개의 워커 노드로 구성된다.
마스터 Node
- 중앙 관리 시스템이다.
- 실제 어플리케이션이 올라가는 공간은 아니다.
- API Server를 실행하며, Cluster를 관리한다.
- 클라우드 환경에서는 GKS, AKS, EKS 등으로 구축할 수 있다.
워커 Node
- 애플리케이션이 실제 실행되는 공간이다. (컨테이너가 동작하는 하나의 서버)
- 단순히 컨테이너를 실행시키는 역할을 한다.
- 참고로, 실습에서 사용한 Minkube는 단일 Node로 이루어진 Cluster 환경이었다.
4. 오브젝트
4-1. K8s Object
- 클러스터에서 관리하는 객체(Entity)이며, 애플리케이션 실행을 정의하는 요소이다.
- 실제 애플리케이션들은 여러 가지 오브젝트를 조합해서 실행된다.
- Pod, Controller, Service 등
- 단순한 "리소스"뿐만 아니라, 상태(state)와 정책(policy)도 포함된다.
- ‘어떤 컨테이너화된 애플리케이션이 동작 중인지 / 어느 노드에서 동작 중인지’를 기술한 상태
- ‘그 애플리케이션이 어떻게 재구동 정책, 업그레이드, 그리고 내고장성과 같은 것에 동작해야 하는지’에 대한 정책등도 포함된다.
4-2. Object 기술
- 우리는 이 오브젝트에 대해 다룰 때 (생성/수정 등) 당연히 API-Server에 요청을 보낼 것이다.
- kubectl CLI 명령어를 사용하여 직접 오브젝트를 생성할 수도 있다.
- 다만, 대부분의 경우 정보를 .yaml 파일로 kubectl에 제공한다.
- kubectl은 API 요청이 이루어질 때, JSON 형식으로 정보를 변환시켜 준다.
- (그래서 JSON 형식 자체로 직접 제공할~ 수도 있기는 하다… 잘 안 쓰지만)
- yaml 파일에는 필수 필드와 오브젝트 스펙(spec)이 포함되어야 한다.
- 외부에서 접근할 수 있도록 API의 리소스 종류(kind)에 맞게 설정/ 생성해야 한다.
- 참고 : K8s 시스템 관련 기능을 수행하는 오브젝트는 대개 ‘kube-system’ namespace에 만들어진다.
- namespace : 컨테이너 별로 논리적인 구분 / 기본적으로 다른 네임스페이스에서는 통신 안됨
[yml 파일 예시]
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Object의 이름과 ID
- 이름(Name) : 같은 네임스페이스 내에서 오브젝트를 구별하는 값
- 같은 네임스페이스 내에서는 같은 종류(kind)의 오브젝트는 같은 이름을 가질 수 없다.
- 유일해야 함!
- 하지만, 다른 종류(kind)라면 같은 이름을 가질 수 있다.
- 예: myapp-1234라는 이름의 Pod와 Deployment는 공존 가능
- UID : 클러스터 전체에서 유일한 오브젝트 식별자 (삭제 후에도 재사용 불가)
5. 워크로드
- 파드 및 이를 관리하는 컨트롤러(ReplicaSet, Deployment 등)의 그룹을 의미하는 개념적인 용어
- 워크로드 자체로는 오브젝트는 아니다.
- 파드와 여러 워크로드 리소스에 대해 배워보자.
💡 쿠버네티스에서 배포할 수 있는 가장 작은 컴퓨트 오브젝트인 파드와, 이를 실행하는 데 도움이 되는 하이-레벨(higher-level) 추상화
출처 : https://kubernetes.io/ko/docs/concepts/workloads/
6. 워크로드 : 파드 (Pod)
6-1. 파드 (Pod) = 실제 실행 단위
- 컨테이너를 실행하기 위한 오브젝트
- Helm Chart 등을 이용해서 리소스 등의 설정을 YAML 파일에 지정
- 한 개 혹은 여러 개의 컨테이너를 실행
- EX) 웹 어플리케이션 구동 시
- 웹 서버 (Nginx + React) → 1개의 컨테이너
- 백엔드 (Spring Boot, Express.js 등) → 1개의 컨테이너
- DB (MySQL, PostgreSQL 등) → 1개의 컨테이너
- 하지만, 하나의 애플리케이션이 여러 컨테이너로 구성될 수도 있다.
- 메인 컨테이너: 웹 애플리케이션
- 사이드카 컨테이너: 로그 수집, 모니터링, 보안 관리
6-2. 파드 실행을 위한 필수 구성 요소
설정 (Configuration)
- 컨테이너 내의 설정값(환경 변수, 비밀번호 등) 정보는 컨테이너 내부에 직접 넣지 말고, 네임스페이스 내에서 안전하게 관리하는 것을 권장한다.
- 즉, ConfigMap 또는 Secret 같은 K8s 리소스를 활용해서 네임스페이스 안에서 관리하는 것이 보안상 더 안전하다.
- 컨테이너에 비밀번호, 혹은 개인 설정을 같이 올리면…
해당 컨테이너를 어딘가 올릴 때, 모두 노출된다.
깃허브에 비밀번호 올리는 것과 같다.
- Pod가 실행될 때, 환경 변수를 통해 참조하는 것이 일반적
- Git-Ci.yaml(GitLab-Ci.yaml) 에서 $임의의 변수으로 설정
- Secret manager, Parameter Store 등에서 암호화해서 실제 Value를 저장해놓고 실행할 때 불러온다.
- Git-Ci.yaml(GitLab-Ci.yaml) 에서 $임의의 변수으로 설정
서비스 (Service)
- Pod는 일시적인 존재!
- IP가 수시로 변한다.
- 따라서, 파드가 외부 클라이언트나 다른 파드와 통신하려면 Service가 필요하다.
- 파드와 클라이언트를 연결하는 역할을 수행
- 클라이언트라 함은 외부 API, 다른 파드, 실제 클라이언트 등 모두 포함한다.
- 클라이언트의 요청을 받을 수 있도록 대표 IP를 취득하여 내부 DNS에 등록한다.
- 대표 IP로 요청 트래픽에 대한 부하분산하여 전송하는 역할을 수행한다.
- Ingress Nginx
스토리지 (Storage)
- 파드는 기본적으로 Statless
- 마치 ‘도커 볼륨’처럼 별도의 스토리지
- 컨테이너의 삭제 → 모든 데이터/로그 삭제
- Persistance Volume을 사용한다.
- 하지만, 퍼시스턴트 볼륨은 K8s 범위에 포함되지 않기 때문에 외부 스토리지를 이용해야 한다.
- 컨테이너 / K8s과 같은 것은 가상화 된 것이기 때문에
또 Scale-up 이 아닌 Scale-out 방식으로 가동되기 때문에
(하나의 EC2의 크기를 키우는 것이 아니라 복제 하여 부하 분산) - → 외부 저장소의 저장은 필수적인 과정이다.
6-3. 파드의 기본 개념
파드의 기본
- 하나의 목적을 위해 만들어진 컨테이너를 부품처럼 조합할 수 있도록 설계한다.
- 파드의 IP주소와 포트번호를 공유한다.
- localhost로 서로 통신할 수 있다.
- 파드이 볼륨을 마운트 하여 파일 시스템 공유가 가능하다.
- (이러한 부분은 도커의 컨테이너와 거의 흡사하기 때문에 그렇게 이해해도 좋다.)
파드는 일시적인 존재
- EKS에서 VPC를 사용하기 때문에,
- 서브넷을 너무 작게 설정하면 ‘IP가 부족하다’고 뜰 가능성이 있다.
- 내부에서 사용하는 ip도 많다.
- 이를테면, 실무에서 이벤트가 늘어나서 파드를 복제한다 ip 부족현상 때문에 실패하는 경우가 많다.
- (실습에서는 큰 문제 없겠지만..)
- 실무에서는 IP 부족 문제가 없도록 Deployment Set에서 서브넷 범위를 넓게 지정하는 게 좋다.
- 파드에 요청을 보낼 때는 반드시 ‘서비스 오브젝트’ 사용
- Controller, Persistent Volumn, ConfigMap/Secret 등의 오브젝트와 함께 사용해야 쿠버네티스를 사용하는 의미가 있는 것이다.

- 파드들에 대한 구성에 대해 많은 지원이 있다.
- Kube Ctl (CLI)
- K8s DashBoard (웹 UI)
- Argo CD
- Cocktail Cloud
- 파드 별로, 컨테이너의 개수는 여러 가지이다.
- Docker를 기반으로 가동
- Docker의 명령어도 쿠버네티스에서 동일하게 자주 사용하게 된다.
- Docker를 기반으로 가동
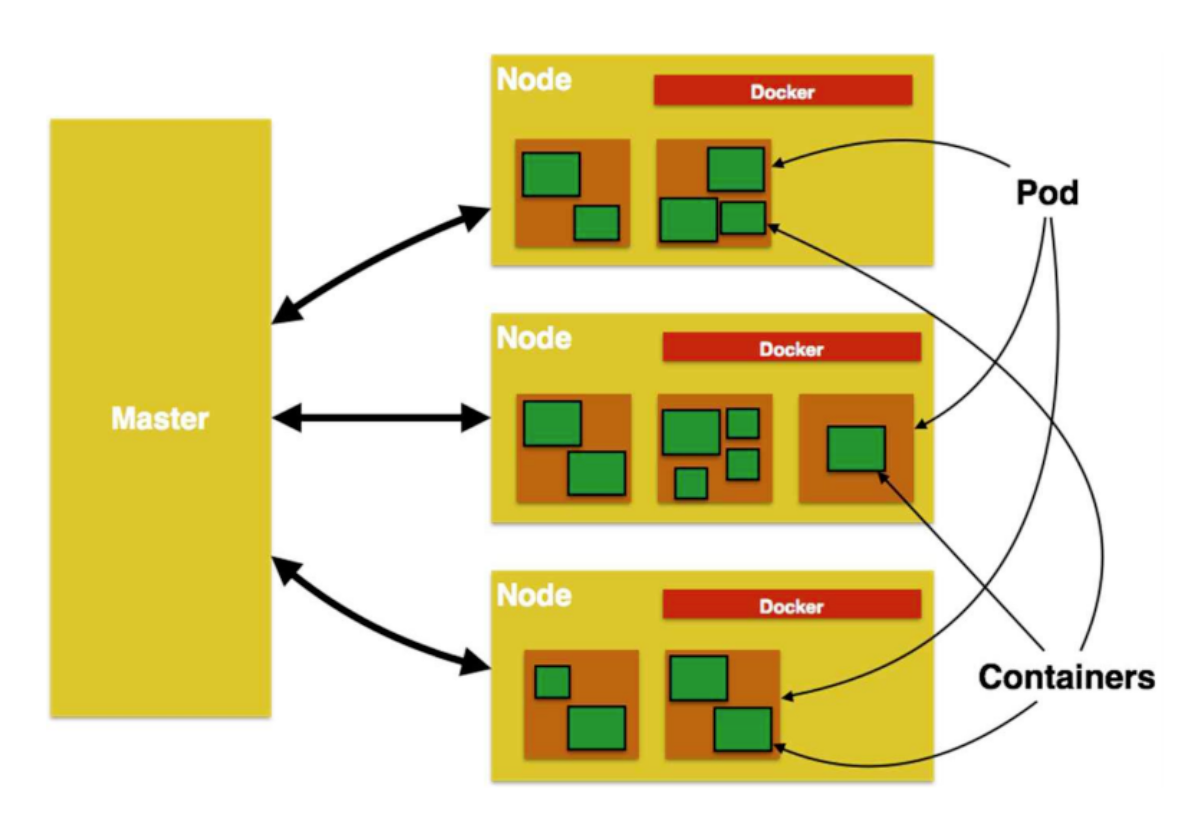
- 파드들은 컨테이너 하나에만 정적으로 있는 것이 아닌, 동적으로 옮겨다니기도 하고, 빈 공간에 띄우기도 한다.
- 스케쥴러가 알아서 조절한다.
- 파드의 확장에 대해서, ‘IP 부족 현상’, ’Worker 노드의 리소스 부족’ 등의 고려가 필요하다.
- 보통 Worker Node로는 EC2를 많이 쓴다
- 이를테면, (4 Core 16 GB) EC2 하나에 6개의 컨테이너 → 20개로 Auto Scaling 진행
- Replica Set에 의해 [EC2의 복제도 필요해진다.]
- → Pod의 적절한 배치
- 이를테면, (4 Core 16 GB) EC2 하나에 6개의 컨테이너 → 20개로 Auto Scaling 진행
- 물리 서버에서의 멀티 노드 아키텍처의 한계
- 온프레미스 환경 / 로컬서버 / Host PC 에서 돌리는 것은 한계가 있다.
- 많은 이벤트 → 스케쥴러에 의해 컨테이너의 확장
- → 🚨 Kube 안의 마스터 노드(kube-apiserver)의 할당이 떨어지는 경우가 있다.
- 리소스 설정이 이렇게 중요하다. (넉넉하게 하는 것이 좋다.)
- 그냥 클라우드 서비스에서 돌리는 것이 좋다.
- 단점은 …비용적인 문제…
6-4. 파드와 Manifast
YAML 형식
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latestJSON 형식
- 프롬포트가 뜨면 kubectl exec -ut ~~ 등을 통해 컨테이너 내부 쉘로 들어갈 수 있다.
- → busybox를 통해 간단히 사용 가능
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "nginx"
},
"spec": {
"containers": [
{
"name": "nginx",
"image": "nginx:latest"
}
]
}
}
6-5. 파드 생성 및 관리
파드 생성 1
- 간단하게 kubectl run 명령어를 사용할 수 있다.
kubectl run <NAME> --image <IMAGE>
kubectl get pods # 파드 실행 확인- kubectl get : docker ps와 비슷한 명령어
- 🚨 파드를 띄웠다고 해도, 서비스를 통해 접속하는 것이기 때문에 localhost로 접속해도 안될 수 있다.
- (노드 포트 등의 네트워크 구성이 필요하다.)
파드 생성 2 - Manifest를 이용
- dockerFile or docker-compose와 유사
- 예시 : mynginx.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
spec:
containers:
- image: nginx
name: mynginxkubectl apply -f mynginx.yaml- 이러한 설정 파일은 클라우드 환경에서 Helm 차트를 이용해 배포할 예정이다.
- ArgoCD를 활용해 Git 저장소(Git URL)와 동기화(Sync)를 맞춘 후, Pod를 배포
- ArgoCD에서 Sync 문제가 발생하면, Pod를 교체하거나 새로운 버전으로 릴리즈
- → 롤링 업데이트 진행 가능
- → 배포할 Pod 개수를 조정하여 스케일링 가능
파드 생성 3 - 매니페스트(Manifest)를 자동 생성
kubectl run ournginx --image=nginx --dry-run=client -o yaml > ournginx.yaml
kubectl apply -f ournginx.yaml- nginx 컨테이너를 실행하는 “Pod YAML 파일”을 생성 → 배포
파드 생성에 관해
- 일반적으로 파드는 직접 생성하지는 않으며, 대신 워크로드 리소스를 사용하여 생성한다.
- Pod는 일시적인 존재
- 일반적으로 싱글톤(singleton) 파드를 포함하여 파드를 직접 만들 필요가 없다.
- 대신, 디플로이먼트(Deployment) 또는 잡(Job)과 같은 워크로드 리소스를 사용하여 생성한다.
- 파드가 상태를 추적해야 한다면, 스테이트풀셋(StatefulSet) 리소스를 고려할 수 있다.
파드 관리
- 실행중인 파드 인스턴스의 로그 확인
- kubectl logs -f
- docker logs -f 와 유사하다.
- -f : 실시간 로그 스트리밍
- --previous (-p) : 컨테이너 이전 인스턴스의 로그의 출력
- 시작과정에서 문제 발생으로 계속 재시작하는 경우 분석에 유용
- 파드가 계속 떨어졌다 붙었다가 반복되는 오류 발생 시
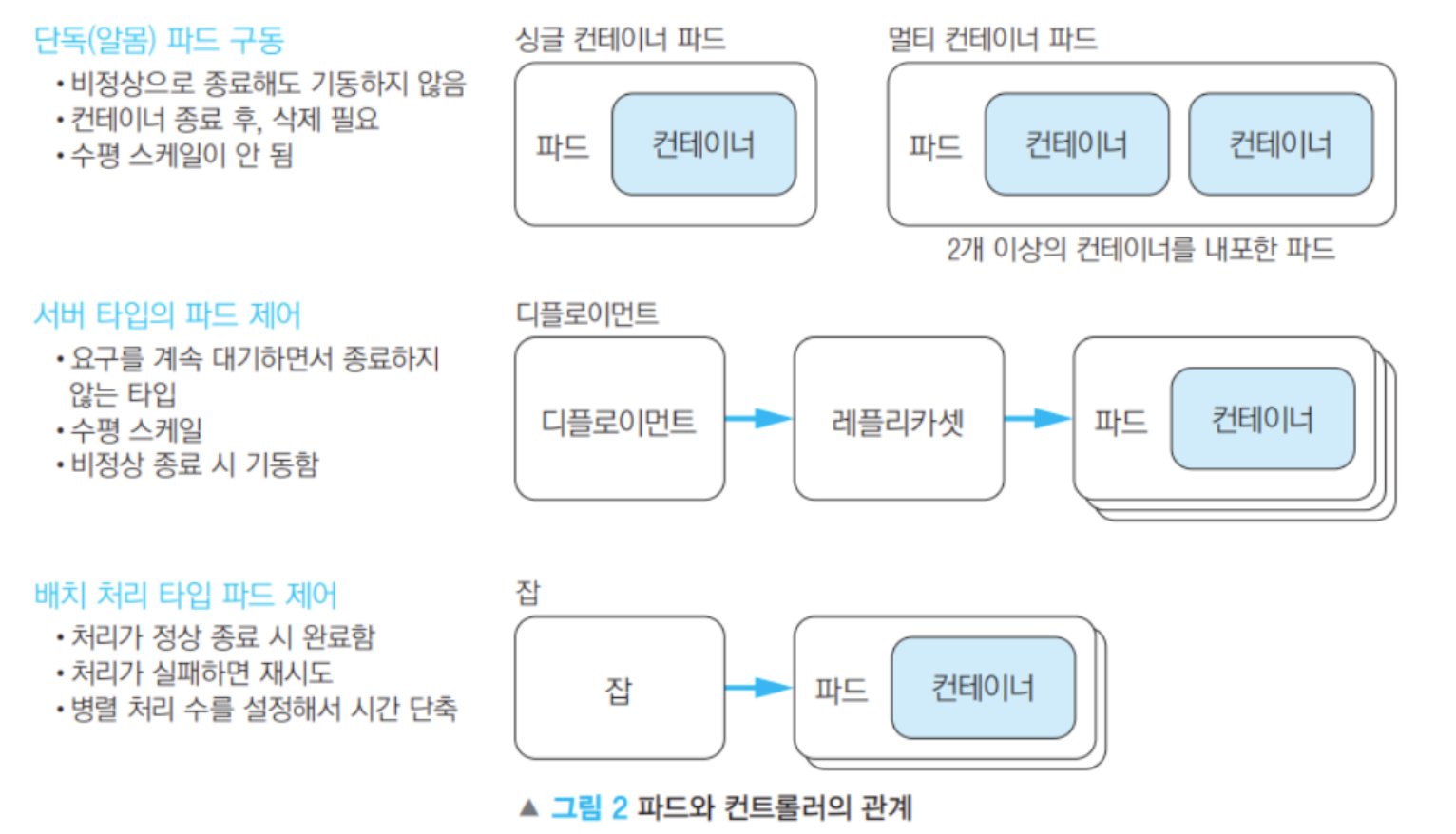
6-6. 파드 배치
- 단독(알몸) 파드
- 컨트롤러 없이 실행 (kubectl run …)
- 비정상 종료 시 재시작 X
- 컨테이너 종료 후 수동 삭제 필요
- 수평 확장 불가
- 서버 타입 파드 (Deployment, StatefulSet)
- 항상 실행하며 요청 대기 (예: 웹 서버, API 서버)
- 수평 스케일링 가능 (replicas 설정)
- 비정상 종료 시 자동 재기동
- 배치 처리 파드 (Job, CronJob)
- 정상 종료 시 완료 (예: 데이터 처리, 크롤링)
- 실패 시 자동 재시도 가능
- 병렬 처리 개수 설정 가능 → 작업 속도 향상
- 단독 파드 → 테스트 용도, 단발성 실행
- 서버 타입 → 항상 실행, 요청 대기, 자동 복구
- 배치 처리 → 작업 후 종료, 실패 시 재시도, 병렬 처리 지원
7. 워크로드 : 워크로드 리소
7-1. 컨트롤러 (Controller)
참고 : 컨트롤러는 쿠버네티스에서 자동화를 담당하는 기능적인 개념. 별도로 존재하는 물리적 컴포넌트나 독립적인 분류 체계가 아니다.
컨트롤러
- 컨트롤러는 "관리하는 주체", 워크로드 리소스는 "관리되는 대상”
- ReplicaSet을 예로 들면
- "ReplicaSet"은 쿠버네티스 오브젝트(Object) 중 워크로드 리소스이고,
- 이를 관리하는 "ReplicaSet 컨트롤러(ReplicaSet Controller)"가 컨트롤러이다.
- (다만, 실무에서는 워크로드 리소스를 그냥 ‘컨트롤러’라고 혼용하여 쓰는 경우도 있다고 한다)
- ReplicaSet을 예로 들면
- 파드를 제어하거나 파드에게 부여할 워크로드의 타입에 따라 적절한 컨트롤러를 선택
- 디플로이먼트, 크론잡 등의 컨트롤러
컨트롤러 작동 원리
쿠버네티스의 컨트롤러는 kube-controller-manager 내부에서 실행된다.
- “1-2. K8s Cluster를 구성하는 코어 프로세스들” 중에서 소개한 컴포넌트
- kube-controller-manager : 다양한 컨트롤러(ReplicaSet, Deployment, Node Controller 등)를 포함
프런트엔드 처리 (워크로드 타입)
- 스마트폰, 컴퓨터, 테블릿 등의 클라이언트의 요청을 직접 받는 워크로드
- 사용자 경험 측면에서 서버 응답이 늦어지지 않는 데에 중점을 둔다
- 이미지 CDN 등의 처리
- 요청에 대응하는 처리를 복수의 파드에서 분단하도록 설계
백엔드 처리 (워크로드 타입)
- 데이터 스토어 : SQL/NoSQL 등
- 캐시 : 세션 정보 공유
- 분산 시스템에서 가장 중요한 데이터 공유에 대한 이야기
- 메시징 : 비동기 시스템 간의 연계 가능
- SQS
- 로그는 동시에 실시간으로 쌓이기 때문에,
타임라인에 따라 차곡차곡 빼놓지 않고 쌓는 것이 매우 중요하다. - 그러나 “병목”에 대한 지점도 고려를 해야하는 것이 중요
- 마이크로 서비스 : 적합한 컨트롤러 처리 중요
- 배치 처리 : 기계 학습, 데이터 분석, 크롤링 등
워크로드 리소스의 종류
- Deployment (디플로이먼트)
- Manifest에 Deployment 작성 후 Kind 작성
- 파드 개수 / 리플리카 등의 설정
- 파드의 수평 확장(스케일링) 및 롤링 업데이트할 때 사용
- Manifest에 Deployment 작성 후 Kind 작성
- StatefulSet (스테이트풀셋)
- 파드 + 볼륨 → 데이터 보관에 초점
- 데이터를 저장하는 서비스(DB 등)용
- Job (잡)
- 배치 작업 실행 후 정상 종료될 때까지 반복
- 파드의 실행 횟수, 동시 실행 개수 등을 설정 가능
- CronJob (크론잡)
- 정기적인 잡 실행 (Crontab과 유사)
- 특정 시간, 주기적으로 잡 생성
- 오류 시 재가동이 필요하다
- -previous : 컨테이너 이전 인스턴스의 로그의 출력
- 이런 오류 상황에서 분석하는 데에 유용
- -previous : 컨테이너 이전 인스턴스의 로그의 출력
- 오류 시 재가동이 필요하다
- DaemonSet (데몬셋)
- 모든 노드에 동일한 파드 실행 (로그 수집, 모니터링, 네트워크 관리 등)
- 대표적인 예시) 로그 수집 후 외부로 빼놓기
- 신규 노드 추가 시 자동으로 해당 파드 배포
- 모든 노드에 동일한 파드 실행 (로그 수집, 모니터링, 네트워크 관리 등)
- ReplicaSet (리플리카셋)
- Deployment 컨트롤러와 연동 → 파드 개수를 일정하게 유지
- 일반적으로 Deployment 내부에서 관리됨 (직접 사용 X)
ReplicationController (레플리케이션 컨트롤러)- ~~이전 버전의 ReplicaSet, 현재는 Deployment가 대체~~

- 보통 배치 처리, 백엔드 서비스의 워크로드 타입을 사용한다.
- 워크로드 타입의 이슈에 따라 컨트롤러 세팅을 하는 것!!!
- 컨트롤러(워크로드 리소스)는 파드 당 하나만 두는 것이 아닌, 섞어서 사용 가능하다.
- 예시) Stateful Controller와 같은 경우에 상태를 유지하는 것이 목적이기 때문에
DB / Kafka (로깅 저장) 등을 활용하며, 이럴 때는 Deployment와 조합해서 사용한다. - ⇒ 상황에 맞게 조합하여 사용
- 예시) Stateful Controller와 같은 경우에 상태를 유지하는 것이 목적이기 때문에
7-2. 디플로이먼트
- 애플리케이션 배포 및 업데이트를 위한 컨트롤러
- 서비스 중단 없이 새로운 버전 배포 가능 (롤링 업데이트, 롤백 지원)
- ReplicaSet을 자동으로 관리하여 파드 개수 조정
- 레이블(Label)과 셀렉터(Selector)를 사용하여 관리할 파드를 식별
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydeploy
spec:
replicas: 10 # 10개의 파드 유지
selector:
matchLabels:
run: nginx
strategy:
type: RollingUpdate # 롤링 업데이트 방식 적용
rollingUpdate:
maxUnavailable: 25% # 동시에 다운될 수 있는 파드 비율
maxSurge: 25% # 동시에 추가 생성할 수 있는 파드 비율
template:
metadata:
labels:
run: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9 # 특정 버전의 nginx 이미지 사용
- ArgoCD를 보면 대시보드를 통해 한눈에 볼 수 있다.
- Pod 구성의 예시
- Deploy - RS - pod

7-3. 리플리카셋
- 컨테이너의 수량 설정
- 만약에 4개 설저 후
- delete pod <replicaset 중 1개>
- 즉시 하나가 새로 살아나서 4개가 된다.
- kubectl delete rs --all → 실제 삭제
- 특정 개수(Replicas)의 파드를 항상 유지하는 쿠버네티스 컨트롤러
- 파드가 삭제되거나 장애가 발생하면 자동으로 새 파드를 생성
- Deployment의 내부에서 사용되며, 직접 생성할 일은 거의 없음
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myreplicaset
spec:
replicas: 2 # 항상 2개의 파드를 유지
selector:
matchLabels:
run: nginx-rs # 관리할 파드 선택 기준
template:
metadata:
labels:
run: nginx-rs # 파드에 적용할 레이블
spec:
containers:
- name: nginx
image: nginx
7-4. 잡
잡과 크론잡
- 모든 컨테이너가 정상적으로 종료할 때까지 재실행한다. (job controller)
- Unix의 크론과 같은 포맷으로 실행 스케줄을 지정할 수 있는 컨트롤러 (cron job)

동작과 주의점
- kubectl get pod로 확인 했을 때 STATUS가 Complete여도 비정상 종료일 수 있다.
- 배치가 잘 동작했는지 보는 것이 우선
쿠버네티스의 잡 컨트롤러
- 지정된 실행 횟수와 병행 개수에 따라 한 개 이상의 파드를 설치한다.
- Job은 모든 컨테이너가 정 상 종료한 경우에만 정상 처리하며 하나라도 비정상이면 전체 비정상
- Job에 기술한 실행 횟수를 전부 종료하면 Job 은 종료 , 비정상 종료에 따른 재실행 횟수 도달 시 종료
- 노드 장애 등 job 파드가 삭제 된 경우 다른 노드 파드에서 재실행한다.
- Job에 의해 실행 된 파드는 job 이 삭제 될 때까지 유지 되다 잡을 삭제 하면 모든 파드는 삭제된다.
7-5. Cron Job
- 정해진 시각에 Job을 만든다.
- 파드의 개수가 정해진 수를 넘어서면 가비지 수집 컨트롤러가 종료된 파드 삭제
- 비정상 종료하면 상한값(n 번 반복) 또는 정상 종료까지 반복한다.

동시 실행과 순차 실행
- 복수의 노드 위에서 여러 파드를 동시에 실행하여 배치처리를 빠르게 완료
- 클라우드에서도 유사한 배치 처리 방식이 존재
- AWS Batch, AWS Lambda, AWS Step Functions
- AWS Convert (비디오/이미지 변환)
- S3 → 이벤트 브릿지(EventBridge) → Lambda 트리거 → 이미지/동영상 처리
- 4K 동영상 변환, 이미지 썸네일 생성 후 다른 저장소(S3, EFS)에 저장
- 이미지 업로드 → S3 저장 → 이벤트 트리거
- Lambda에서 이미지 썸네일 생성 → 새로운 S3 버킷에 저장
- S3에 저장된 썸네일 이미지를 CloudFront를 통해 캐싱하여 최적화된 속도로 제공
- 이 과정에서의 동기화 문제
- Lambda(비동기 처리방식) → 동기 실행
- CloudFront 캐시 무효화
- 새 썸네일이 업로드되면 기존 캐시를 제거
- DynamoDB 또는 Redis를 사용하여 락(Lock) 메커니즘 적용
- 동일한 이미지에 대해 여러 개의 썸네일 생성 요청이 들어오면 불필요한 중복 작업 발생

메시지 브로커와의 조합
- 크론잡 배치 처리 + 메시지 브로커 조합 (병렬 처리 최적화)
- 컨테이너 하나당 처리할 수 있는 작업량에는 한계가 있음 (CPU, 메모리 제약)
- 대량의 데이터 처리 시 병렬 실행이 필요
- 메시지 브로커(RabbitMQ, Kafka, SQS 등)와 조합하여 크론잡을 분산 실행 가능

8. 워크로드 응용
8-1. 초기화 전용 컨테이너 (Init Container)
초기화 컨테이너
- 초기화 컨테이너는 메인 컨테이너 실행 전, 필수적인 초기 작업을 수행하는 컨테이너
- 순차적으로 실행되며, 모든 초기화 컨테이너가 완료되어야 메인 컨테이너가 실행된다
- 외부 서비스 대기, 설정 파일 생성, 볼륨 준비 등의 작업에 유용하게 사용된다.
- 예시 : 볼륨 준비
- 공유 볼륨을 설정하고, 권한을 변경하는 작업
- 이 작업을 "메인 컨테이너 실행 전에 반드시 수행해야 하므로" Init Container로 설정함.
apiVersion: v1
kind: Pod
metadata:
name: init-sample
spec:
initContainers: # 메인 컨테이너 실행 전에 초기화 컨테이너 실행
- name: init
image: alpine
command: ["/bin/sh"]
args: ["-c", "mkdir /mnt/html; chown 33:33 /mnt/html"]
volumeMounts:
- mountPath: /mnt # 볼륨 마운트 경로
name: data-vol
readOnly: false
containers:
- name: main # 메인 컨테이너
image: ubuntu
command: ["/bin/sh"]
args: ["-c", "tail -f /dev/null"]
volumeMounts:
- mountPath: /docs # 공유 볼륨 마운트 경로
name: data-vol
readOnly: false
volumes:
- name: data-vol
emptyDir: {} # 파드 내부에서 공유되는 빈 디렉터리 볼륨
8-2. Pod의 Health Check 기능
활성 프로브 (Active Probe)
- 주기적인 GET 요청을 보낸다
- 200 : 정상
- 500 응답의 반복 : 서버 정지
- 로드 밸런서(ALB, NLB) 로드밸런서의 동작 기능이나 Kubelet의 동작 기능이나 똑같이 사용된다.
- 참고
- ALB/NLB는 AWS에서 제공하는 클라우드 기반 로드 밸런서
- ALB (Application Load Balancer) 또는 NLB (Network Load Balancer)는
EC2 인스턴스를 대상으로 타겟 그룹(Target Group)을 구성
→ 주기적으로 헬스 체크
- 단순히 로드밸런싱만?
- 그냥 UnHealthy → 서버 꺼짐
- Auto Sacaling 까지 연계해야 제대로 된 사용!
- 대체 인스턴스 추가
- 최소 / 최대 개수 설정
- 참고
- Manifest에 명시적으로 설정 필요
apiVersion: v1
kind: Pod # 이렇게 kind 설정이 중요, 종류에 따라 아래 동작 방식이 달라짐
metadata:
name: webapi
spec:
containers:
- name: webapi
image: maho/webapi:0.1
livenessProbe:
# (1) 핸들러를 구현한 애플리케이션
# (2) 애플리케이션이 살아있는지 확인
httpGet:
path: /healthz # 확인 경로
port: 3000
initialDelaySeconds: 3 # 프로브 시작 대기 시간
periodSeconds: 5 # 검사 간격
readinessProbe:
# (3) 애플리케이션이 준비되었는지 확인
httpGet:
path: /ready # 확인 경로
port: 3000
initialDelaySeconds: 15 # 프로브 검사 시작 전 대기 시간
periodSeconds: 6 # 검사 간격- 파드 내 초기화만을 수행하는 컨테이너와 요청 처리를 하는 컨테이너를 별도로 개발하여 재사용
- 스토리지를 마운트 할때 새로운 디렉터리를 만들어 소유자를 변경한 후 데이터를 저장 하는 초기화 처리
- initContainer 를 먼저 실행하여 공유 볼륨을 /mnt에 마운트 , /mnt/html 폴더를 추가 후 소유자를 변경
- 이후 메인 컨테이너가 기동되어 해당 공유 볼륨을 마운트하여 사용한다.
8-3. 사이드카 패턴 - Dockerfile
- 하나의 파드 안에 여러 개의 컨테이너를 담아서 동시에 실행하는 패턴
- 웹서버 컨테이너 + 최신 콘텐츠를 깃허브에서 다운받는 컨테이너 = 사이드카
- 즉, 메인 애플리케이션 컨테이너와 보조 기능을 수행하는 컨테이너를 함께 배포하는 패턴

사이드카 패턴 사용 이유
- 애플리케이션 변경 없이, 사이드카를 붙였다 떼거나 교체하기 쉬운 구성 방식이다.
주의할 점
- 메인과 사이드카 컨테이너가 같은 노드에서 실행되므로 리소스 설정이 중요하다.
- 두 컨테이너 간 의존성 관리가 필요하다.
- 사이드카 컨테이너는 메인 컨테이너 보다 나중에 시작/종료 해야 한다.

8-4. 애플리케이션 버전 변경 전략
1) 재생성 전략 (Recreate)
- 재배포!
- 디플로이먼트와 관련된 모든 포드를 중지 → 새로운 버전의 포드를 생성
- 장점 : 쉽고 간편하다
- 단점 : 서비스 다운타임이 발생한다.
- 서비스에 영향이 있다.
- 기능 테스트 배포에 적합하다.

2) 롤링 업데이트 전략 (Rolling Update)
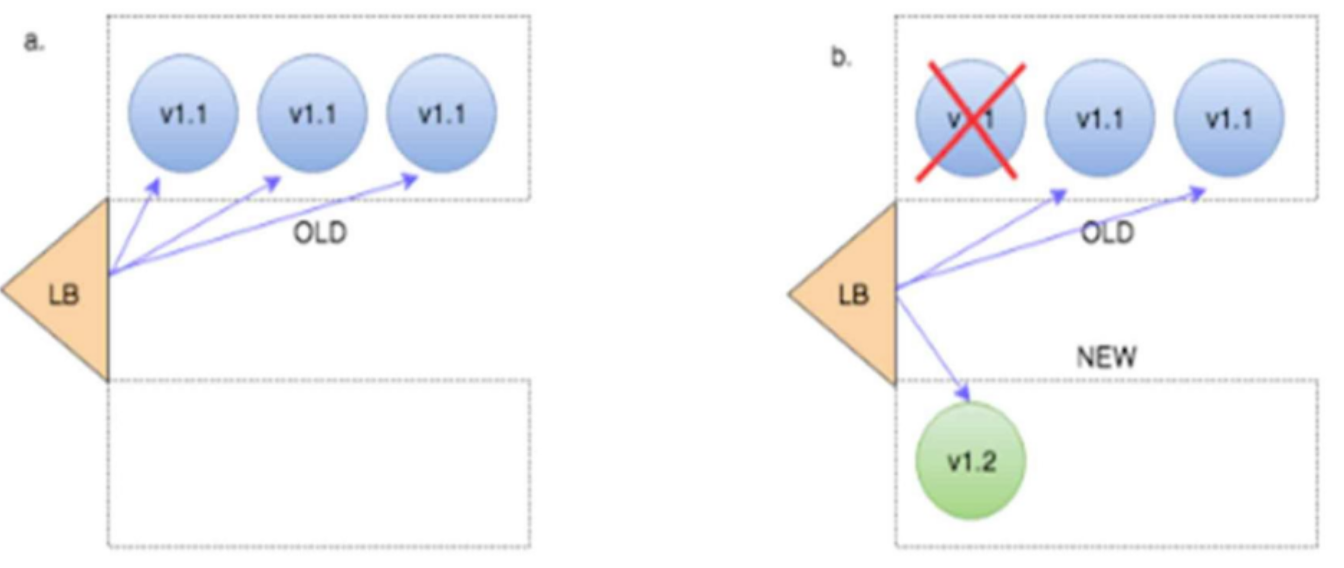
- Blue / Green 배포 방식과 유사
- 기존 버전의 애플리케이션을 점진적으로 새로운 버전으로 교체하는 배포 방식
- 트래픽을 기존 버전(V1.1)과 새 버전(V1.2)으로 분산하면서 배포
- 사실 사용자 경험 측면에서는 서버가 내려갔다는 것도 못 느끼지만,
아주 희박한 환경에서의 에러가 난다면?- 기존 v1.1에 있던 사용자
- 로그아웃
- 심한 경우 500 에러
- [그런데 결제 중이었다면?]
- 실제 결제는 되었는데, 사용자는 v1.2로 옮겨가고 사이트에서는 재결제가 뜸
- → ALB에서 Connection Draining(연결 지연 종료) 기술
- 기존 V1.1에서 요청을 처리 중인 사용자가 있다면
해당 요청이 끝날 때까지 기다린다. - 모든 연결이 종료된 후, 완전히 전환
- 세션이 끊길 때 대기하는 것
- 기존 V1.1에서 요청을 처리 중인 사용자가 있다면
- 완벽한 해결일까?
- 기존 연결이 강제 종료되는 문제를 해결하지만, 세션 유지 문제는 해결하지 못함
- 1) 세션 기반 애플리케이션 (로그인, 결제 등)은 해결되지 않음
- Connection Draining은 진행 중인 요청만 유지해줄 뿐, 새 요청까지 보장하지 않음
- 세션이 메모리에 저장되어 있다면, 서버 교체 시 세션이 사라질 가능성 있음
- 결제 진행 중일 때 사용자가 새로운 버전(V1.2)으로 이동하면 세션이 끊기고 재로그인 요구
- 2) 웹소켓, 장기 연결(Long-lived connections)에 취약
- WebSocket 같은 경우, 클라이언트가 지속적으로 서버와 연결을 유지함
- Connection Draining이 끝난 후에는 새로운 서버(V1.2)로 강제 이동해야 함
- 3) 완전한 무중단 배포가 어려움
- 기존 요청을 마친 후 서버를 종료하더라도, 세션을 공유하지 않으면 로그인 유지가 불가능
- Sticky Session을 설정하면 해결 가능하지만, 서버가 교체되면 Sticky Session도 의미가 없음
- ⇒ 실무 : Connection Draining + 세션 공유(redis 등) + Canary 배포 활용
- 세션 공유
- 세션을 서버에 저장하면 배포 시 세션이 사라지므로, 반드시 중앙 저장소 사용 필요
- Redis, Memcached 같은 세션 스토리지
- 레디스락..?
- Canary 배포
- 일부 사용자(예: 1~5%)만 새 버전으로 전환 후 안정성이 확인되면 전체 배포
- 롤백 가능
- 단점 : 리소스를 두 배로 사용… 비용 증가
- 이중 트랜잭션 처리 → DB + 메시지 큐(Kafka, SQS)를 활용하여 트랜잭션 상태 유지
- Idempotency Key 적용 → 중복 요청을 방지하여 결제가 두 번 이루어지지 않도록 함
- 트랜잭션 스토리지 사용 (DynamoDB, Kafka, SQS 등)
- 세션 공유
- 기존 v1.1에 있던 사용자
- ⇒ 그냥 이런 기능있네? 좋다! 도입하자!
- 가 아닌 “서비스” 레이어의 WorkFlow를 생각하는 것이 아키텍쳐 / 기술 선택에서 중요하다.
9. 서비스
9-1. 서비스
서비스 필요의 이유
- Pod에도 고유 IP가 있기는 함!
- 하지만, Pod는 생성/삭제될 때마다 IP가 변경됨.
- → 서비스는 고정된 "대표 IP(Cluster IP)"를 제공하여 안정적인 접근을 가능하게 함.
- DNS 기반의 서비스 검색 기능을 지원하여, 서비스 이름을 통해 접근 가능
- 트래픽을 여러 Pod에 분산하는 로드밸런서 역할도 수행한다.
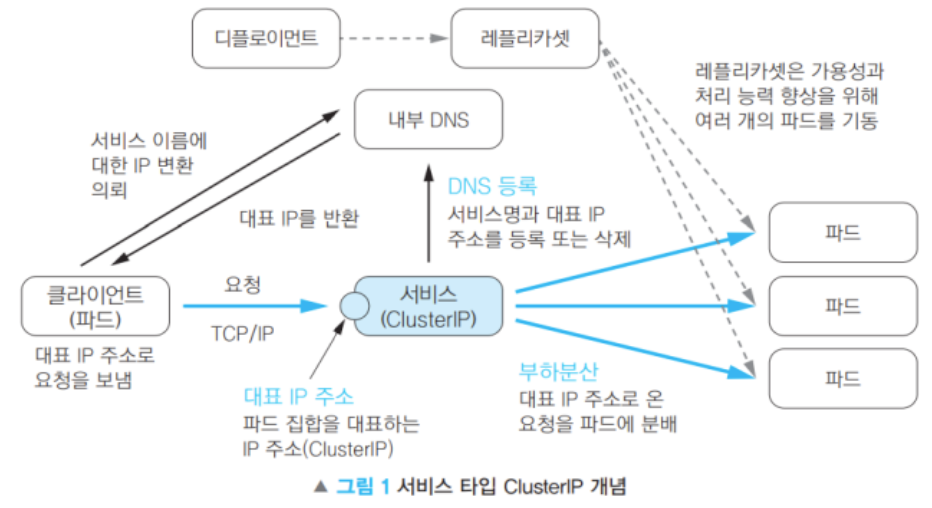
서비스의 동작 순서 (ClusterIP)

- 대표 IP를 통해 클라이언트 요청을 받음.
- Docker는 -p 8080:80 설정 후 직접 접근 가능
- K8s는 반드시 서비스를 통해 Pod까지 접근해야 함
- 내부 DNS에 서비스 이름을 등록하여 클라이언트가 서비스 이름으로 접근 가능.
- 셀렉터(Selector)를 사용하여 특정 라벨(Label)을 가진 파드로 트래픽을 전달.
- 서비스가 생성된 후 실행된 컨테이너는 자동으로 환경 변수를 설정하여 서비스 정보를 얻을 수 있음.
Cluster IP (대표 IP)
- Pod들의 그룹을 대표하여, 대표 IP(Cluster IP)를 가진다.
- Cluster IP : 내부에서 작동하는 IP
- 파드의 IP주소를 내부 DNS에 직접 설정한다.
환경 변수
- 서비스 만들어진 후 생성되는 파드의 컨테이너는 환경 변수가 설정됨
- → 이 환경 변수를 이용하여 서비스의 대표 IP를 얻을 수 있다.
9-2. 부하분산과 어피니티
부하분산
- 대표 IP 주소에 도착한 Request들은 라벨(Labels)과 셀렉터(Selectors)이 일치하는 파드를 찾아 전송하게 된다.
- 같은 라벨을 가진 파드가 여러 개라면, 부하분산은 Default로 랜덤임.
- 여러 Pod에 대한 로드밸런싱 풀을 구성하여, 부하를 분산
어피니티
- 요청받는 파드를 고정하고 싶은 경우
- session Affinity 항목에 Cluster IP를 설정
- HTTP 헤드 안의 쿠키 값에 따라 전송되는 파드의 고정을 원하는 경우 인그레스 이용
- 리버스 프록시 값에 따라 이동
10. 서비스 종류 ; 클러스터 네트워킹
- 쿠버네티스에는 4가지 대응해야 할 네트워킹 문제가 있다.
- 고도로 결합된 컨테이너 간의 통신: localhost 통신
- 파드 간 통신 : 이전에 다룬 ClusterIP로 해결
- 파드와 서비스 간 통신 : 서비스(ClusterIP, NodePort) 활용
- 외부와 서비스 간 통신 : NodePort, LoadBalancer, Ingress 사용
10-1. ClusterIP (Default) : 클러스터 내부 전용
- 내부의 다른 파드에서만 접근 가능
- 서비스 타입을 지정하지 않으면 → Cluster IP로 만들어진다.
[서비스 예시]
- spec.type 설정이 없으면 Default로 ClusterIP
apiVersion: v1
kind: Service
metadata:
name: myservice # Service 이름 (kubectl get svc myservice로 조회 가능)
# namespace: default # 네임스페이스에 생성 : 설정 없으면 'default'
labels:
hello: world # Service에 'hello: world' 라벨 부여
spec:
ports:
- port: 8080 # Service가 노출하는 포트 (ClusterIP 기준)
protocol: TCP
targetPort: 80 # 실제 Pod 내부에서 실행 중인 컨테이너의 포트 (nginx의 기본 포트 80)
selector:
run: mynginx # 이 Service가 라우팅할 Pod 선택 (라벨 'run=mynginx'인 Pod과 연결)
(1) Pod IP로 직접 요청 보내기
- Pod IP로 직접 요청을 보내는 것도 가능하다.
# mynginx Pod의 Ip 확인
kubectl get pod -owide
# client -> mynginx Pod의 Ip로 전송
kubectl exec client -- curl -s 10.244.0.85
# mynginx -> client Pod의 Ip로 전송
kubectl exec mynginx -- curl -s 10.244.0.85- 하지만, Pod는 생성/삭제될 때마다 IP가 변경되며, 서비스를 활용해 고정된 "Cluster IP"로 통신하는 것이 좋다고 했다.
(2) ClusterIP를 통해 요청 보내기
# 서비스 IP (Cluster IP) 확인
kubectl get svc
# Cluster IP로 요청 (myservice 서비스)
kubectl exec client -- curl -s <myservice Cluster IP>:8080
(3) Service Discovery : DNS를 통해 서비스 이름으로 요청 보내기]
# 서비스 이름 (DNS)로 요청
kubectl exec mynginx -- curl -s myservice:8080
10-2. NodePort : 클러스터 내부 + 외부
- Cluster IP의 기능에 더해진 것
- 공개 포트가 오픈된다. (30000~32767)
- 각 노드가 수령한 요청은 대상 파드들에 부하분산된다. (정식서비스에 사용하는 것은 비추천)
- 외부에서도 각 노드의 IP/ 특정 포트로 접근 가능
- 내부적으로도 각 Worker 노드간에 통신할 수 있다!
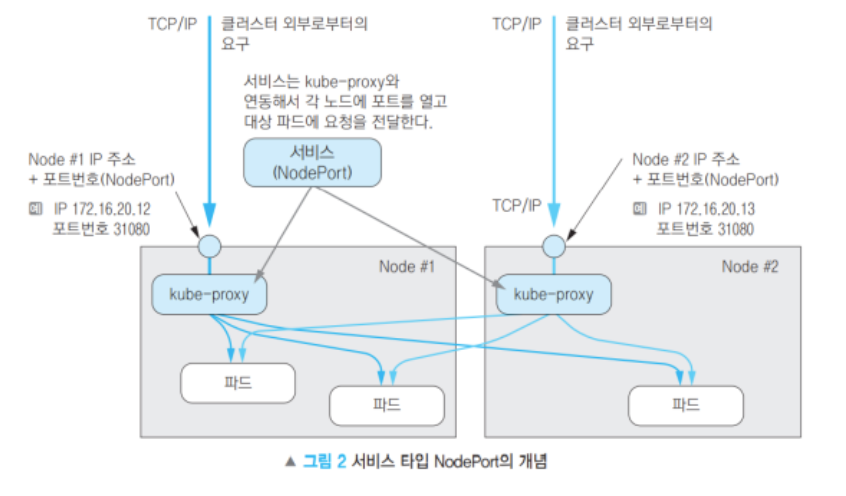
10-3. LoadBalancer : 클러스터 내부 + 외부 (대표 IP 제공)
- 로드밸런서[ALB, NLB]와 연동 → 외부에 공개
- 로드밸런서는 NodePort를 사용하기 때문에 Cluster IP도 자동할당 된다.
- 퍼블릭 클라우드 환경(AWS)에서 제공되는 로드밸런서와도 연동 가능
- → ALB로 들어온다.
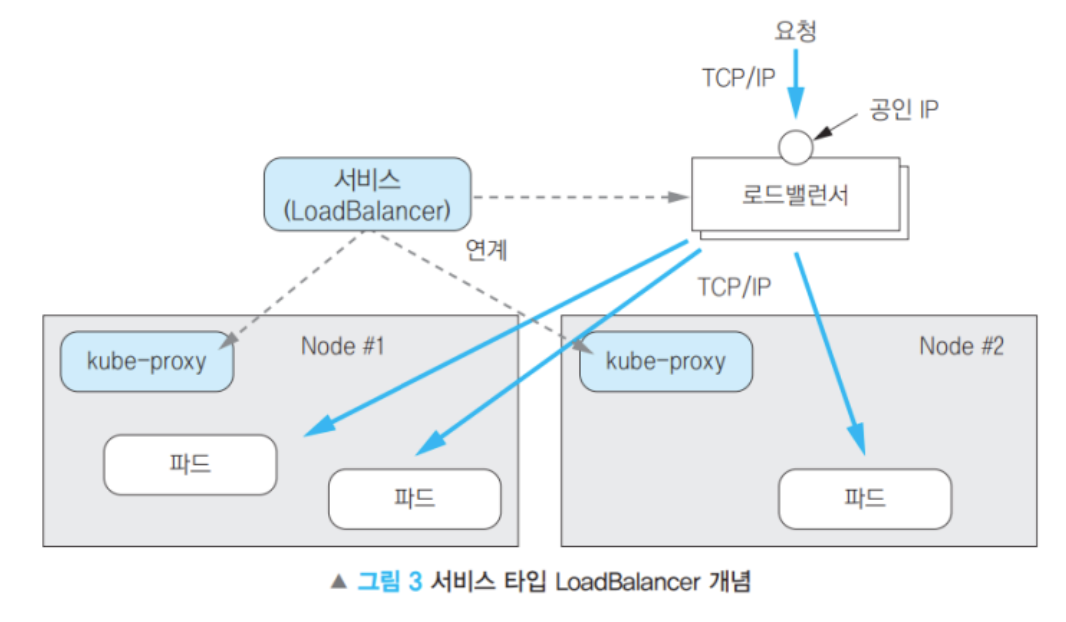
10-4. ExternalName : 외부 서비스 연결
- 외부의 엔드포인트에 접속하기 위한 이름을 해결
- 퍼블릭 클라우드의 DB나 외부 API 서비스등을 접근할 때 사용
- 서비스의 이름과 외부 DNS 이름의 매핑을 내부 DNS에 설정
- 외부 엔드포인트에 접근 가능
- 포트까지 지정은 불가능

10-5. 서비스와 파드의 연결

- 서비스는 셀렉터(Selector)와 라벨(Label)을 이용해 특정 파드에 트래픽을 보냄.
- 서비스가 자동으로 환경 변수를 설정하여 컨테이너에서 쉽게 접근 가능.
- 부하 분산(Load Balancing) 기능이 기본 제공됨.
⇒ "ClusterIP"는 기본값이며, 외부 접근이 필요하면 "NodePort" 또는 "LoadBalancer"를 사용해야 한다.
11. 인그레스 (Ingress) : 외부와 서비스 간 통신
- Ingress는 쿠버네티스 클러스터 내부의 서비스(Service)와 외부 트래픽을 연결시켜준다.
- ⇒ 파드에서 실행 중인 애플리케이션을 클러스터 외부에서 접근 할 수 있다.
- 로드밸런싱, HTTPS 적용, 도메인 기반 호스팅 등 다양한 기능 제공
- 기존의 로드밸런서를 대체할 수 있다.
- → 하나의 엔드포인트를 통해 여러 서비스에 접근 가능

11-1. 공개 URL과 애플리케이션 매핑
- Ingress는 외부에서 들어오는 URL 요청을 내부 애플리케이션(서비스/파드)로 매핑하는 역할
- 도메인 기반 라우팅을 지원하며, 여러 애플리케이션을 하나의 Ingress 리소스에서 관리 가능
- Selector : Match Label
- 예시) Web : Oreder
- 각 파드들이 연결
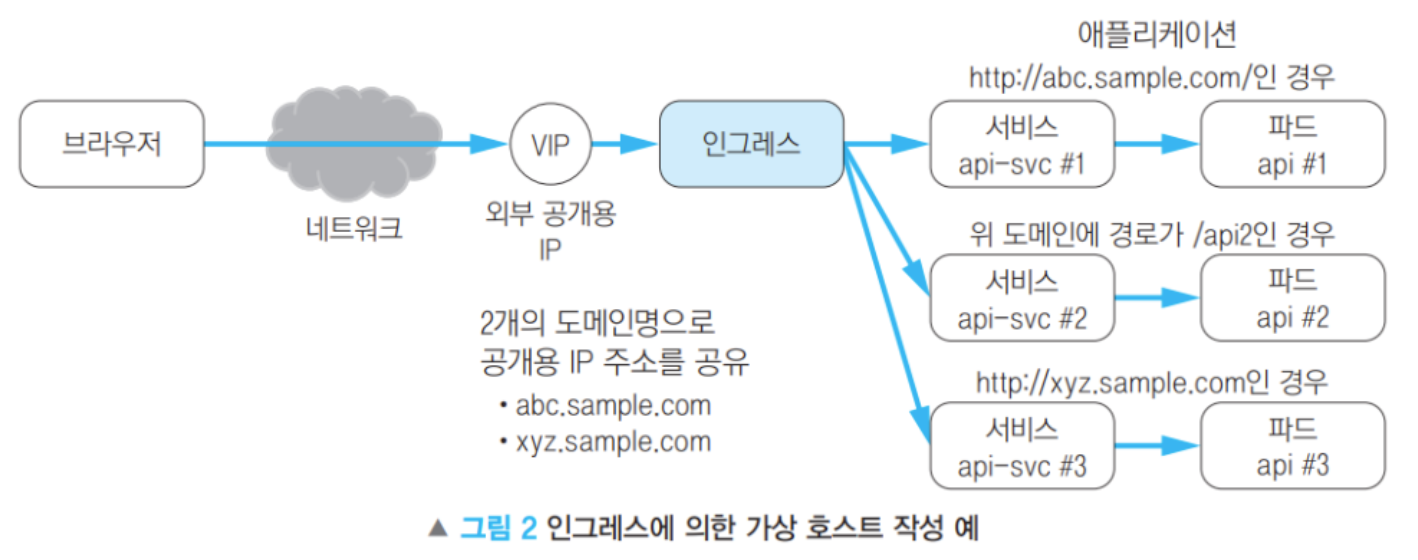
kubernetes.io/ingress.class: "nginx"
- 클러스터 내에 여러 Ingress 컨트롤러(Nginx, Traefik 등)가 있을 경우, 특정 컨트롤러를 지정할 필요가 있음.
- 위 설정이 없으면 모든 Ingress 컨트롤러가 요청을 처리하려고 할 수 있음
nginx.ingress.kubernetes.io/rewrite-target: /URL
- 기본적으로 클라이언트의 요청 URL(/reservation, /order)을 그대로 전달
- 하지만 백엔드 서비스에서 /reservation 같은 경로가 필요 없을 경우, 이 설정을 사용해 URL을 /로 변경
- 예제에서 /reservation 요청이 들어와도 api-reservation-svc에서는 /로 인식하여 처리 가능
- 이 설정이 없으면 클라이언트 요청을 그대로 전송하여 FIle NotFound 에러가 발생한다.
ConfigMap을 이용한 Nginx 설정 적용 (미들웨어 설정)
- Nginx, Apache 같은 미들웨어 설정을 ConfigMap을 사용하여 동적으로 관리 가능
- ConfigMap을 마운트하면 파드가 파일 시스템처럼 설정 값을 읽을 수 있음
11-2. 모더니제이션과 세션 어피니티(Session Affinity)
- 웹 애플리케이션에서는 로드밸런서의 세션 어피니티가 일반적
- 브라우저는 무상태(Stateless) 프로토콜이므로 클라이언트-서버 간 세션 유지 불가
- 세션 정보를 기반으로 로드밸런서가 동일한 서버로 요청을 유지해야 함
- ⇒ 쿠버네티스의 세션 어피니티(Session Affinity)
세션 어피니티(Session Affinity) ; Client IP 기반
- 로드밸런서나 Kubernetes Service가 클라이언트의 IP를 기반으로 세션을 유지
- 클라이언트의 IP를 기반으로 특정 Pod에 지속적으로 연결하는 방식
- 로드밸런서가 같은 클라이언트의 요청을 항상 같은 서버(Pod)로 보내는 기능
- 쿠키가 필요 없고, TCP/UDP 같은 HTTP가 아닌 프로토콜에서도 사용 가능
- 🚨 단점 : 클라이언트의 IP가 변하면 다른 Pod로 연결될 수 있음 (모바일, VPN 등 IP 변동이 많은 환경 사용 시 문제 발생)
+ Sticky Session ; Cookie 기반
- 클라이언트 요청이 특정 Pod로 유지되도록 로드밸런서에서 쿠키를 발급하여 관리
- 일반적으로 HTTP 쿠키(Set-Cookie 헤더)를 활용하여 세션을 유지
- 클라이언트가 보낸 요청을 항상 같은 Pod로 보냄 (서버 메모리에 저장된 세션 유지 목적)
- NGINX Ingress 에서 MY_SESSION이라는 쿠키가 설정되면, 클라이언트는 항상 같은 Pod로 연결됨
- 🚨 단점 : 하지만, Pod가 삭제되면 쿠키 세션이 유지되지 않음 (이러한 경우, 외부 세션 저장소 필요)
11-3. HPA 설정
- Horizontal Pod Autoscaler
- 리소스 사용량(CPU, 메모리 등)에 따라 자동으로 Pod의 개수를 조정하는 기능
- Ingress와 HPA를 함께 사용하여 트래픽 증가 시 자동으로 Pod를 확장할 수 있다.
- 특정 Deployment 또는 ReplicaSet을 모니터링하며,
리소스 사용량이 기준을 초과하면 자동으로 Pod를 추가 / 감소하면 Pod를 감소
Deployment/ReplicaSet VS HPA ?
- Deployment/ReplicaSet
- "고정된 개수의 Pod"를 운영
- 수동으로 임의 값을 지정하여 pod에 대한 확장, 기존 컨테이너 유지 등의 기능을 제공
- (물론 Selfhealing등은 현재 컨테이너를 유지하기위해 자동으로 동작)
- HPA
- "동적으로 Pod 개수”를 조절
- HPA의 경우 Metric Server와 연계되어 CPU, MEM, Network 등의 메트릭 값을 이용하여 동적으로 컨테이너를 확장하는 개념
- HPA는 메트릭값에 의해 동적으로 조작
12. 로드밸런싱
Flannel
- 간단한 L3 네트워크
Calico
- 접근 제어 기능 추가 제공
- Master - worker
- worker - → Calico 설정 안하면, 노드간 통신 불가능
- 모든 네트워크 설정이 끝나면 꼭 Calico 설정이 필요하다.
13. 스토리지
13-1. 스토리지
Docker Volume과 비슷한 개념
- 대표적으로 Log 저장
- 외부 스터리지를 사용하고자 할 때
- 전용 스토리지 + 서버 클러스터링 두 가지를 조합한 방법
- 외부 스토리지의 논리적인 볼륨을 Pod 내부에 마운트하는 것을 의미한다.
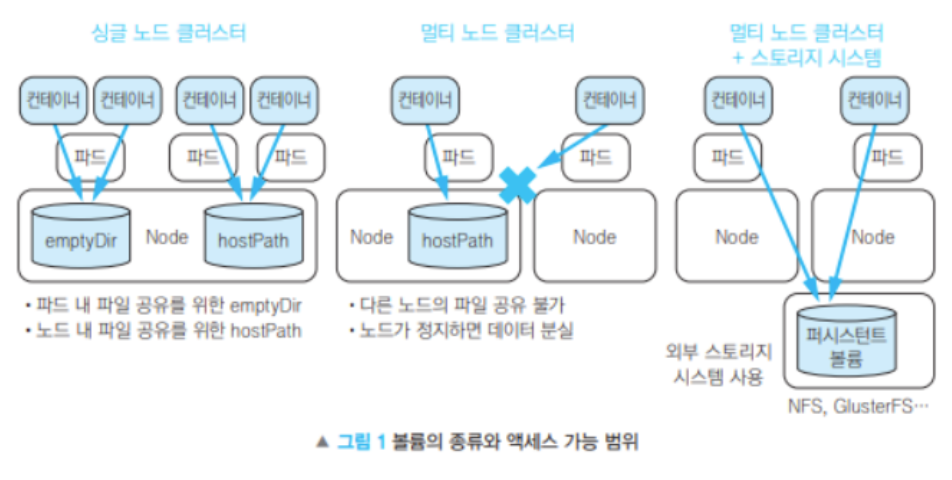
13-2. 스토리지 사용 방식 비교
| 스토리지 방식 | 설명 |
예시 |
|---|---|---|
| 전용 스토리지 (Dedicated Storage) | 특정 스토리지에 직접 연결하여 사용 | AWS EBS, NFS, Ceph |
| SDS (Software-Defined Storage) | 여러 서버를 클러스터링하여 저장 공간을 공유 | GlusterFS, Ceph, Longhorn |
| 하이브리드 (Dedicated + SDS) | 전용 스토리지와 SDS를 조합하여 고가용성 제공 | Ceph + EBS 조합 |
- EBS (gp2, gp3)
- 인스턴스 생성 설정할 때 AWS에서의 스토리지 구성 화면

- 외부 스토리지 시스템의 API 사용하여 볼륨을 자동으로 준비해 주는 방법 (동적)
- 외부 스토리지 시스템의 설정을 직접 진행하는 방법 (수동)
- “Demon Set을 이용해서 S3에 적재하는 방식”도 있다.
- PV/PVC는 Kubernetes에서 관리하는 "마운트된 스토리지"를 의미
- 이 방식은 직접 S3 같은 오브젝트 스토리지에 데이터를 저장하는 접근법
<오브젝트 스토리지(S3)> - 실무에서 자주 사용
반응형
반응형
0. Kubernetes 개요
쿠버네티스란?
- 컨테이너화된 애플리케이션을 자동으로 배포하고 관리하는 오케스트레이션 도구
- 도커는 컨테이너화해서 이미지를 만드는 것이라고 했다.
- 쿠버네티스는 컨테이너가 실행될 환경을 만들고, 이를 효과적으로 관리하는 역할을 한다.
- 즉, “컨테이너의 실행/관리/운영 환경”을 제공하는 것
1. 쿠버네티스 컴포넌트
1-1. K8s Cluster
- 쿠버네티스를 배포하면 Cluster를 얻는다.
- 쿠버네티스 클러스터 = 하나의 실행 환경(Infrastructure Environment)
- K8s 클러스터는 최소 한 개의 Worker Node를 가진다.
- Node는 쉽게 말해 ‘서버’라고 생각하면 편하다.
- Worker Node는 애플리케이션을 구성하는 Pod를 실행하는 역할을 한다.
- 미리 설명하자면, 하나의 Pod는 여러 개의 컨테이너로 구성될 수 있으며,
- 이 Pod가 바로 K8s의 최소 실행 단위이다.
- 다만, K8s가 제대로 동작하기 위해서는 내부적으로 다양한 코어 프로세스(컴포넌트)가 필요하다.
1-2. K8s Cluster를 구성하는 코어 프로세스들
- K8s 클러스터를 “소프트웨어 구성” 관점으로도 구분할 수 있다.
- Control Plane Components와 Node Componets로 구성된다.
- Control Plane Components = 마스터 노드에서 실행되는 관리 프로세스들
- Node Componets = 워커 노드에서 실행되는 실행 프로세스들
Control Plane Componets
- 클러스터의 상태를 조정하고 관리하는 역할을 한다.
- 보통 마스터 노드에서 실행된다.
- 참고 : 고가용성 클러스터 환경에서는 여러 노드에 분산될 수도 있다.
| 구성 요소 | 역할 |
|---|---|
| kube-apiserver | API 요청을 처리하고 클러스터 상태를 관리 |
| etcd | 클러스터의 모든 상태 데이터를 저장하는 분산 키-값 저장소 |
| kube-scheduler | 새로운 파드를 실행할 최적의 노드를 선택 |
| kube-controller-manager | 노드, 파드, 레플리카 관리 등 다양한 컨트롤러 실행 |
| cloud-controller-manager | 클라우드 서비스(AWS, GCP 등)와 연계 |
Node Componets
- 컨테이너(Pod)를 실행하고 네트워크를 관리하는 역할을 한다.
- 워커 노드에서 실행된다.
| 컴포넌트 | 역할 |
|---|---|
| kubelet | 각 노드에서 파드 실행 및 상태 관리 |
| kube-proxy | 네트워크 트래픽 라우팅 및 로드 밸런싱 수행 |
| 컨테이너 런타임 (containerd, Docker) | 컨테이너 실행 엔진 |
| CNI 플러그인(Flannel, Calico 등) | 노드 간 네트워크 연결 |
참고 : 에드온
- 코어(핵심) 프로세스는 아니지만, 기본적으로 제공하는 컴포넌트 들도 있다.
- 기본 기능을 확장하는 추가 컴포넌트들이다.
- Kubernetes Dashboard
- 웹 UI 기반의 클러스터 관리 도구이다.
- CLI에서는 kubectl 명령어로 Api를 보냈다.
- 웹 UI 기반의 클러스터 관리 도구이다.
2. 쿠버네티스 API
- 쿠버네티스 조작은 모두 API로 동작한다.
- 우리가 CLI에서 kubectl 명령어로 보내는 모든 작업들은 마스터 노드 내부의 “API Server(kube-apiserver)”에 도착한다.
- API Server가 "쿠버네티스의 중앙 게이트웨이" 역할을 하면서 모든 요청을 받아서 처리하는 구조이다.
- 알아서 적절한 컴포넌트로 요청이 전달!
- K8s Dashboard (웹 UI), 직접 API 호출, Terraform (내부적으로 kube-apiserver API 호출) 등으로도 호출할 수 있지만,
- 어떤 방법으로든 쿠버네티스를 조작하든, 결국 API 요청이 kube-apiserver로 전달된다.
3. 쿠버네티스 아키텍처
3-1. 컨테이너 (Container)
Container에 대한 용어를 잠시 짚고 넘어가보자.
- 그냥 Docker Container 로 이해하면 된다.
- 실제 애플리케이션이 실행되는 환경
- 다만, 단독으로 존재하지 않고 반드시 "파드(Pod)" 내부에서 실행된다!
- 단독 실행은 불가능 (K8s는 컨테이너 실행 도구가 아니다!!!)
3-2. 노드 (Node)
- 컨테이너(Pod)를 실행하는 단위가 되는 머신(서버)이다.
- 노드는 물리 서버일 수도 있고, 가상 머신(VM)일 수도 있다.
- 이후 클라우드 환경에서 K8s를 다루는 것을 배울 예정이므로 쉽게 ‘EC2 = Node’ 라고 생각해도 된다.
- K8s 클러스터를 “물리적인 구성” 관점에서 노드 별로 구분할 수 있다.
- 기능별로 “마스터 노드”와 “워커 노드”로 구분된다.
- 보통 1개 이상의 마스터 노드 + 여러 개의 워커 노드로 구성된다.
마스터 Node
- 중앙 관리 시스템이다.
- 실제 어플리케이션이 올라가는 공간은 아니다.
- API Server를 실행하며, Cluster를 관리한다.
- 클라우드 환경에서는 GKS, AKS, EKS 등으로 구축할 수 있다.
워커 Node
- 애플리케이션이 실제 실행되는 공간이다. (컨테이너가 동작하는 하나의 서버)
- 단순히 컨테이너를 실행시키는 역할을 한다.
- 참고로, 실습에서 사용한 Minkube는 단일 Node로 이루어진 Cluster 환경이었다.
4. 오브젝트
4-1. K8s Object
- 클러스터에서 관리하는 객체(Entity)이며, 애플리케이션 실행을 정의하는 요소이다.
- 실제 애플리케이션들은 여러 가지 오브젝트를 조합해서 실행된다.
- Pod, Controller, Service 등
- 단순한 "리소스"뿐만 아니라, 상태(state)와 정책(policy)도 포함된다.
- ‘어떤 컨테이너화된 애플리케이션이 동작 중인지 / 어느 노드에서 동작 중인지’를 기술한 상태
- ‘그 애플리케이션이 어떻게 재구동 정책, 업그레이드, 그리고 내고장성과 같은 것에 동작해야 하는지’에 대한 정책등도 포함된다.
4-2. Object 기술
- 우리는 이 오브젝트에 대해 다룰 때 (생성/수정 등) 당연히 API-Server에 요청을 보낼 것이다.
- kubectl CLI 명령어를 사용하여 직접 오브젝트를 생성할 수도 있다.
- 다만, 대부분의 경우 정보를 .yaml 파일로 kubectl에 제공한다.
- kubectl은 API 요청이 이루어질 때, JSON 형식으로 정보를 변환시켜 준다.
- (그래서 JSON 형식 자체로 직접 제공할~ 수도 있기는 하다… 잘 안 쓰지만)
- yaml 파일에는 필수 필드와 오브젝트 스펙(spec)이 포함되어야 한다.
- 외부에서 접근할 수 있도록 API의 리소스 종류(kind)에 맞게 설정/ 생성해야 한다.
- 참고 : K8s 시스템 관련 기능을 수행하는 오브젝트는 대개 ‘kube-system’ namespace에 만들어진다.
- namespace : 컨테이너 별로 논리적인 구분 / 기본적으로 다른 네임스페이스에서는 통신 안됨
[yml 파일 예시]
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Object의 이름과 ID
- 이름(Name) : 같은 네임스페이스 내에서 오브젝트를 구별하는 값
- 같은 네임스페이스 내에서는 같은 종류(kind)의 오브젝트는 같은 이름을 가질 수 없다.
- 유일해야 함!
- 하지만, 다른 종류(kind)라면 같은 이름을 가질 수 있다.
- 예: myapp-1234라는 이름의 Pod와 Deployment는 공존 가능
- UID : 클러스터 전체에서 유일한 오브젝트 식별자 (삭제 후에도 재사용 불가)
5. 워크로드
- 파드 및 이를 관리하는 컨트롤러(ReplicaSet, Deployment 등)의 그룹을 의미하는 개념적인 용어
- 워크로드 자체로는 오브젝트는 아니다.
- 파드와 여러 워크로드 리소스에 대해 배워보자.
💡 쿠버네티스에서 배포할 수 있는 가장 작은 컴퓨트 오브젝트인 파드와, 이를 실행하는 데 도움이 되는 하이-레벨(higher-level) 추상화
출처 : https://kubernetes.io/ko/docs/concepts/workloads/
6. 워크로드 : 파드 (Pod)
6-1. 파드 (Pod) = 실제 실행 단위
- 컨테이너를 실행하기 위한 오브젝트
- Helm Chart 등을 이용해서 리소스 등의 설정을 YAML 파일에 지정
- 한 개 혹은 여러 개의 컨테이너를 실행
- EX) 웹 어플리케이션 구동 시
- 웹 서버 (Nginx + React) → 1개의 컨테이너
- 백엔드 (Spring Boot, Express.js 등) → 1개의 컨테이너
- DB (MySQL, PostgreSQL 등) → 1개의 컨테이너
- 하지만, 하나의 애플리케이션이 여러 컨테이너로 구성될 수도 있다.
- 메인 컨테이너: 웹 애플리케이션
- 사이드카 컨테이너: 로그 수집, 모니터링, 보안 관리
6-2. 파드 실행을 위한 필수 구성 요소
설정 (Configuration)
- 컨테이너 내의 설정값(환경 변수, 비밀번호 등) 정보는 컨테이너 내부에 직접 넣지 말고, 네임스페이스 내에서 안전하게 관리하는 것을 권장한다.
- 즉, ConfigMap 또는 Secret 같은 K8s 리소스를 활용해서 네임스페이스 안에서 관리하는 것이 보안상 더 안전하다.
- 컨테이너에 비밀번호, 혹은 개인 설정을 같이 올리면…
해당 컨테이너를 어딘가 올릴 때, 모두 노출된다.
깃허브에 비밀번호 올리는 것과 같다.
- Pod가 실행될 때, 환경 변수를 통해 참조하는 것이 일반적
- Git-Ci.yaml(GitLab-Ci.yaml) 에서 $임의의 변수으로 설정
- Secret manager, Parameter Store 등에서 암호화해서 실제 Value를 저장해놓고 실행할 때 불러온다.
- Git-Ci.yaml(GitLab-Ci.yaml) 에서 $임의의 변수으로 설정
서비스 (Service)
- Pod는 일시적인 존재!
- IP가 수시로 변한다.
- 따라서, 파드가 외부 클라이언트나 다른 파드와 통신하려면 Service가 필요하다.
- 파드와 클라이언트를 연결하는 역할을 수행
- 클라이언트라 함은 외부 API, 다른 파드, 실제 클라이언트 등 모두 포함한다.
- 클라이언트의 요청을 받을 수 있도록 대표 IP를 취득하여 내부 DNS에 등록한다.
- 대표 IP로 요청 트래픽에 대한 부하분산하여 전송하는 역할을 수행한다.
- Ingress Nginx
스토리지 (Storage)
- 파드는 기본적으로 Statless
- 마치 ‘도커 볼륨’처럼 별도의 스토리지
- 컨테이너의 삭제 → 모든 데이터/로그 삭제
- Persistance Volume을 사용한다.
- 하지만, 퍼시스턴트 볼륨은 K8s 범위에 포함되지 않기 때문에 외부 스토리지를 이용해야 한다.
- 컨테이너 / K8s과 같은 것은 가상화 된 것이기 때문에
또 Scale-up 이 아닌 Scale-out 방식으로 가동되기 때문에
(하나의 EC2의 크기를 키우는 것이 아니라 복제 하여 부하 분산) - → 외부 저장소의 저장은 필수적인 과정이다.
6-3. 파드의 기본 개념
파드의 기본
- 하나의 목적을 위해 만들어진 컨테이너를 부품처럼 조합할 수 있도록 설계한다.
- 파드의 IP주소와 포트번호를 공유한다.
- localhost로 서로 통신할 수 있다.
- 파드이 볼륨을 마운트 하여 파일 시스템 공유가 가능하다.
- (이러한 부분은 도커의 컨테이너와 거의 흡사하기 때문에 그렇게 이해해도 좋다.)
파드는 일시적인 존재
- EKS에서 VPC를 사용하기 때문에,
- 서브넷을 너무 작게 설정하면 ‘IP가 부족하다’고 뜰 가능성이 있다.
- 내부에서 사용하는 ip도 많다.
- 이를테면, 실무에서 이벤트가 늘어나서 파드를 복제한다 ip 부족현상 때문에 실패하는 경우가 많다.
- (실습에서는 큰 문제 없겠지만..)
- 실무에서는 IP 부족 문제가 없도록 Deployment Set에서 서브넷 범위를 넓게 지정하는 게 좋다.
- 파드에 요청을 보낼 때는 반드시 ‘서비스 오브젝트’ 사용
- Controller, Persistent Volumn, ConfigMap/Secret 등의 오브젝트와 함께 사용해야 쿠버네티스를 사용하는 의미가 있는 것이다.
- 파드들에 대한 구성에 대해 많은 지원이 있다.
- Kube Ctl (CLI)
- K8s DashBoard (웹 UI)
- Argo CD
- Cocktail Cloud
- 파드 별로, 컨테이너의 개수는 여러 가지이다.
- Docker를 기반으로 가동
- Docker의 명령어도 쿠버네티스에서 동일하게 자주 사용하게 된다.
- Docker를 기반으로 가동
- 파드들은 컨테이너 하나에만 정적으로 있는 것이 아닌, 동적으로 옮겨다니기도 하고, 빈 공간에 띄우기도 한다.
- 스케쥴러가 알아서 조절한다.
- 파드의 확장에 대해서, ‘IP 부족 현상’, ’Worker 노드의 리소스 부족’ 등의 고려가 필요하다.
- 보통 Worker Node로는 EC2를 많이 쓴다
- 이를테면, (4 Core 16 GB) EC2 하나에 6개의 컨테이너 → 20개로 Auto Scaling 진행
- Replica Set에 의해 [EC2의 복제도 필요해진다.]
- → Pod의 적절한 배치
- 이를테면, (4 Core 16 GB) EC2 하나에 6개의 컨테이너 → 20개로 Auto Scaling 진행
- 물리 서버에서의 멀티 노드 아키텍처의 한계
- 온프레미스 환경 / 로컬서버 / Host PC 에서 돌리는 것은 한계가 있다.
- 많은 이벤트 → 스케쥴러에 의해 컨테이너의 확장
- → 🚨 Kube 안의 마스터 노드(kube-apiserver)의 할당이 떨어지는 경우가 있다.
- 리소스 설정이 이렇게 중요하다. (넉넉하게 하는 것이 좋다.)
- 그냥 클라우드 서비스에서 돌리는 것이 좋다.
- 단점은 …비용적인 문제…
6-4. 파드와 Manifast
YAML 형식
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latestJSON 형식
- 프롬포트가 뜨면 kubectl exec -ut ~~ 등을 통해 컨테이너 내부 쉘로 들어갈 수 있다.
- → busybox를 통해 간단히 사용 가능
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "nginx"
},
"spec": {
"containers": [
{
"name": "nginx",
"image": "nginx:latest"
}
]
}
}
6-5. 파드 생성 및 관리
파드 생성 1
- 간단하게 kubectl run 명령어를 사용할 수 있다.
kubectl run <NAME> --image <IMAGE>
kubectl get pods # 파드 실행 확인- kubectl get : docker ps와 비슷한 명령어
- 🚨 파드를 띄웠다고 해도, 서비스를 통해 접속하는 것이기 때문에 localhost로 접속해도 안될 수 있다.
- (노드 포트 등의 네트워크 구성이 필요하다.)
파드 생성 2 - Manifest를 이용
- dockerFile or docker-compose와 유사
- 예시 : mynginx.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
spec:
containers:
- image: nginx
name: mynginx
kubectl apply -f mynginx.yaml- 이러한 설정 파일은 클라우드 환경에서 Helm 차트를 이용해 배포할 예정이다.
- ArgoCD를 활용해 Git 저장소(Git URL)와 동기화(Sync)를 맞춘 후, Pod를 배포
- ArgoCD에서 Sync 문제가 발생하면, Pod를 교체하거나 새로운 버전으로 릴리즈
- → 롤링 업데이트 진행 가능
- → 배포할 Pod 개수를 조정하여 스케일링 가능
파드 생성 3 - 매니페스트(Manifest)를 자동 생성
kubectl run ournginx --image=nginx --dry-run=client -o yaml > ournginx.yaml
kubectl apply -f ournginx.yaml- nginx 컨테이너를 실행하는 “Pod YAML 파일”을 생성 → 배포
파드 생성에 관해
- 일반적으로 파드는 직접 생성하지는 않으며, 대신 워크로드 리소스를 사용하여 생성한다.
- Pod는 일시적인 존재
- 일반적으로 싱글톤(singleton) 파드를 포함하여 파드를 직접 만들 필요가 없다.
- 대신, 디플로이먼트(Deployment) 또는 잡(Job)과 같은 워크로드 리소스를 사용하여 생성한다.
- 파드가 상태를 추적해야 한다면, 스테이트풀셋(StatefulSet) 리소스를 고려할 수 있다.
파드 관리
- 실행중인 파드 인스턴스의 로그 확인
- kubectl logs -f
- docker logs -f 와 유사하다.
- -f : 실시간 로그 스트리밍
- --previous (-p) : 컨테이너 이전 인스턴스의 로그의 출력
- 시작과정에서 문제 발생으로 계속 재시작하는 경우 분석에 유용
- 파드가 계속 떨어졌다 붙었다가 반복되는 오류 발생 시
6-6. 파드 배치
- 단독(알몸) 파드
- 컨트롤러 없이 실행 (kubectl run …)
- 비정상 종료 시 재시작 X
- 컨테이너 종료 후 수동 삭제 필요
- 수평 확장 불가
- 서버 타입 파드 (Deployment, StatefulSet)
- 항상 실행하며 요청 대기 (예: 웹 서버, API 서버)
- 수평 스케일링 가능 (replicas 설정)
- 비정상 종료 시 자동 재기동
- 배치 처리 파드 (Job, CronJob)
- 정상 종료 시 완료 (예: 데이터 처리, 크롤링)
- 실패 시 자동 재시도 가능
- 병렬 처리 개수 설정 가능 → 작업 속도 향상
- 단독 파드 → 테스트 용도, 단발성 실행
- 서버 타입 → 항상 실행, 요청 대기, 자동 복구
- 배치 처리 → 작업 후 종료, 실패 시 재시도, 병렬 처리 지원
7. 워크로드 : 워크로드 리소
7-1. 컨트롤러 (Controller)
참고 : 컨트롤러는 쿠버네티스에서 자동화를 담당하는 기능적인 개념. 별도로 존재하는 물리적 컴포넌트나 독립적인 분류 체계가 아니다.
컨트롤러
- 컨트롤러는 "관리하는 주체", 워크로드 리소스는 "관리되는 대상”
- ReplicaSet을 예로 들면
- "ReplicaSet"은 쿠버네티스 오브젝트(Object) 중 워크로드 리소스이고,
- 이를 관리하는 "ReplicaSet 컨트롤러(ReplicaSet Controller)"가 컨트롤러이다.
- (다만, 실무에서는 워크로드 리소스를 그냥 ‘컨트롤러’라고 혼용하여 쓰는 경우도 있다고 한다)
- ReplicaSet을 예로 들면
- 파드를 제어하거나 파드에게 부여할 워크로드의 타입에 따라 적절한 컨트롤러를 선택
- 디플로이먼트, 크론잡 등의 컨트롤러
컨트롤러 작동 원리
쿠버네티스의 컨트롤러는 kube-controller-manager 내부에서 실행된다.
- “1-2. K8s Cluster를 구성하는 코어 프로세스들” 중에서 소개한 컴포넌트
- kube-controller-manager : 다양한 컨트롤러(ReplicaSet, Deployment, Node Controller 등)를 포함
프런트엔드 처리 (워크로드 타입)
- 스마트폰, 컴퓨터, 테블릿 등의 클라이언트의 요청을 직접 받는 워크로드
- 사용자 경험 측면에서 서버 응답이 늦어지지 않는 데에 중점을 둔다
- 이미지 CDN 등의 처리
- 요청에 대응하는 처리를 복수의 파드에서 분단하도록 설계
백엔드 처리 (워크로드 타입)
- 데이터 스토어 : SQL/NoSQL 등
- 캐시 : 세션 정보 공유
- 분산 시스템에서 가장 중요한 데이터 공유에 대한 이야기
- 메시징 : 비동기 시스템 간의 연계 가능
- SQS
- 로그는 동시에 실시간으로 쌓이기 때문에,
타임라인에 따라 차곡차곡 빼놓지 않고 쌓는 것이 매우 중요하다. - 그러나 “병목”에 대한 지점도 고려를 해야하는 것이 중요
- 마이크로 서비스 : 적합한 컨트롤러 처리 중요
- 배치 처리 : 기계 학습, 데이터 분석, 크롤링 등
워크로드 리소스의 종류
- Deployment (디플로이먼트)
- Manifest에 Deployment 작성 후 Kind 작성
- 파드 개수 / 리플리카 등의 설정
- 파드의 수평 확장(스케일링) 및 롤링 업데이트할 때 사용
- Manifest에 Deployment 작성 후 Kind 작성
- StatefulSet (스테이트풀셋)
- 파드 + 볼륨 → 데이터 보관에 초점
- 데이터를 저장하는 서비스(DB 등)용
- Job (잡)
- 배치 작업 실행 후 정상 종료될 때까지 반복
- 파드의 실행 횟수, 동시 실행 개수 등을 설정 가능
- CronJob (크론잡)
- 정기적인 잡 실행 (Crontab과 유사)
- 특정 시간, 주기적으로 잡 생성
- 오류 시 재가동이 필요하다
- -previous : 컨테이너 이전 인스턴스의 로그의 출력
- 이런 오류 상황에서 분석하는 데에 유용
- -previous : 컨테이너 이전 인스턴스의 로그의 출력
- 오류 시 재가동이 필요하다
- DaemonSet (데몬셋)
- 모든 노드에 동일한 파드 실행 (로그 수집, 모니터링, 네트워크 관리 등)
- 대표적인 예시) 로그 수집 후 외부로 빼놓기
- 신규 노드 추가 시 자동으로 해당 파드 배포
- 모든 노드에 동일한 파드 실행 (로그 수집, 모니터링, 네트워크 관리 등)
- ReplicaSet (리플리카셋)
- Deployment 컨트롤러와 연동 → 파드 개수를 일정하게 유지
- 일반적으로 Deployment 내부에서 관리됨 (직접 사용 X)
ReplicationController (레플리케이션 컨트롤러)- ~~이전 버전의 ReplicaSet, 현재는 Deployment가 대체~~
- 보통 배치 처리, 백엔드 서비스의 워크로드 타입을 사용한다.
- 워크로드 타입의 이슈에 따라 컨트롤러 세팅을 하는 것!!!
- 컨트롤러(워크로드 리소스)는 파드 당 하나만 두는 것이 아닌, 섞어서 사용 가능하다.
- 예시) Stateful Controller와 같은 경우에 상태를 유지하는 것이 목적이기 때문에
DB / Kafka (로깅 저장) 등을 활용하며, 이럴 때는 Deployment와 조합해서 사용한다. - ⇒ 상황에 맞게 조합하여 사용
- 예시) Stateful Controller와 같은 경우에 상태를 유지하는 것이 목적이기 때문에
7-2. 디플로이먼트
- 애플리케이션 배포 및 업데이트를 위한 컨트롤러
- 서비스 중단 없이 새로운 버전 배포 가능 (롤링 업데이트, 롤백 지원)
- ReplicaSet을 자동으로 관리하여 파드 개수 조정
- 레이블(Label)과 셀렉터(Selector)를 사용하여 관리할 파드를 식별
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydeploy
spec:
replicas: 10 # 10개의 파드 유지
selector:
matchLabels:
run: nginx
strategy:
type: RollingUpdate # 롤링 업데이트 방식 적용
rollingUpdate:
maxUnavailable: 25% # 동시에 다운될 수 있는 파드 비율
maxSurge: 25% # 동시에 추가 생성할 수 있는 파드 비율
template:
metadata:
labels:
run: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9 # 특정 버전의 nginx 이미지 사용
- ArgoCD를 보면 대시보드를 통해 한눈에 볼 수 있다.
- Pod 구성의 예시
- Deploy - RS - pod
7-3. 리플리카셋
- 컨테이너의 수량 설정
- 만약에 4개 설저 후
- delete pod <replicaset 중 1개>
- 즉시 하나가 새로 살아나서 4개가 된다.
- kubectl delete rs --all → 실제 삭제
- 특정 개수(Replicas)의 파드를 항상 유지하는 쿠버네티스 컨트롤러
- 파드가 삭제되거나 장애가 발생하면 자동으로 새 파드를 생성
- Deployment의 내부에서 사용되며, 직접 생성할 일은 거의 없음
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myreplicaset
spec:
replicas: 2 # 항상 2개의 파드를 유지
selector:
matchLabels:
run: nginx-rs # 관리할 파드 선택 기준
template:
metadata:
labels:
run: nginx-rs # 파드에 적용할 레이블
spec:
containers:
- name: nginx
image: nginx
7-4. 잡
잡과 크론잡
- 모든 컨테이너가 정상적으로 종료할 때까지 재실행한다. (job controller)
- Unix의 크론과 같은 포맷으로 실행 스케줄을 지정할 수 있는 컨트롤러 (cron job)
동작과 주의점
- kubectl get pod로 확인 했을 때 STATUS가 Complete여도 비정상 종료일 수 있다.
- 배치가 잘 동작했는지 보는 것이 우선
쿠버네티스의 잡 컨트롤러
- 지정된 실행 횟수와 병행 개수에 따라 한 개 이상의 파드를 설치한다.
- Job은 모든 컨테이너가 정 상 종료한 경우에만 정상 처리하며 하나라도 비정상이면 전체 비정상
- Job에 기술한 실행 횟수를 전부 종료하면 Job 은 종료 , 비정상 종료에 따른 재실행 횟수 도달 시 종료
- 노드 장애 등 job 파드가 삭제 된 경우 다른 노드 파드에서 재실행한다.
- Job에 의해 실행 된 파드는 job 이 삭제 될 때까지 유지 되다 잡을 삭제 하면 모든 파드는 삭제된다.
7-5. Cron Job
- 정해진 시각에 Job을 만든다.
- 파드의 개수가 정해진 수를 넘어서면 가비지 수집 컨트롤러가 종료된 파드 삭제
- 비정상 종료하면 상한값(n 번 반복) 또는 정상 종료까지 반복한다.
동시 실행과 순차 실행
- 복수의 노드 위에서 여러 파드를 동시에 실행하여 배치처리를 빠르게 완료
- 클라우드에서도 유사한 배치 처리 방식이 존재
- AWS Batch, AWS Lambda, AWS Step Functions
- AWS Convert (비디오/이미지 변환)
- S3 → 이벤트 브릿지(EventBridge) → Lambda 트리거 → 이미지/동영상 처리
- 4K 동영상 변환, 이미지 썸네일 생성 후 다른 저장소(S3, EFS)에 저장
- 이미지 업로드 → S3 저장 → 이벤트 트리거
- Lambda에서 이미지 썸네일 생성 → 새로운 S3 버킷에 저장
- S3에 저장된 썸네일 이미지를 CloudFront를 통해 캐싱하여 최적화된 속도로 제공
- 이 과정에서의 동기화 문제
- Lambda(비동기 처리방식) → 동기 실행
- CloudFront 캐시 무효화
- 새 썸네일이 업로드되면 기존 캐시를 제거
- DynamoDB 또는 Redis를 사용하여 락(Lock) 메커니즘 적용
- 동일한 이미지에 대해 여러 개의 썸네일 생성 요청이 들어오면 불필요한 중복 작업 발생
메시지 브로커와의 조합
- 크론잡 배치 처리 + 메시지 브로커 조합 (병렬 처리 최적화)
- 컨테이너 하나당 처리할 수 있는 작업량에는 한계가 있음 (CPU, 메모리 제약)
- 대량의 데이터 처리 시 병렬 실행이 필요
- 메시지 브로커(RabbitMQ, Kafka, SQS 등)와 조합하여 크론잡을 분산 실행 가능
8. 워크로드 응용
8-1. 초기화 전용 컨테이너 (Init Container)
초기화 컨테이너
- 초기화 컨테이너는 메인 컨테이너 실행 전, 필수적인 초기 작업을 수행하는 컨테이너
- 순차적으로 실행되며, 모든 초기화 컨테이너가 완료되어야 메인 컨테이너가 실행된다
- 외부 서비스 대기, 설정 파일 생성, 볼륨 준비 등의 작업에 유용하게 사용된다.
- 예시 : 볼륨 준비
- 공유 볼륨을 설정하고, 권한을 변경하는 작업
- 이 작업을 "메인 컨테이너 실행 전에 반드시 수행해야 하므로" Init Container로 설정함.
apiVersion: v1
kind: Pod
metadata:
name: init-sample
spec:
initContainers: # 메인 컨테이너 실행 전에 초기화 컨테이너 실행
- name: init
image: alpine
command: ["/bin/sh"]
args: ["-c", "mkdir /mnt/html; chown 33:33 /mnt/html"]
volumeMounts:
- mountPath: /mnt # 볼륨 마운트 경로
name: data-vol
readOnly: false
containers:
- name: main # 메인 컨테이너
image: ubuntu
command: ["/bin/sh"]
args: ["-c", "tail -f /dev/null"]
volumeMounts:
- mountPath: /docs # 공유 볼륨 마운트 경로
name: data-vol
readOnly: false
volumes:
- name: data-vol
emptyDir: {} # 파드 내부에서 공유되는 빈 디렉터리 볼륨
8-2. Pod의 Health Check 기능
활성 프로브 (Active Probe)
- 주기적인 GET 요청을 보낸다
- 200 : 정상
- 500 응답의 반복 : 서버 정지
- 로드 밸런서(ALB, NLB) 로드밸런서의 동작 기능이나 Kubelet의 동작 기능이나 똑같이 사용된다.
- 참고
- ALB/NLB는 AWS에서 제공하는 클라우드 기반 로드 밸런서
- ALB (Application Load Balancer) 또는 NLB (Network Load Balancer)는
EC2 인스턴스를 대상으로 타겟 그룹(Target Group)을 구성
→ 주기적으로 헬스 체크
- 단순히 로드밸런싱만?
- 그냥 UnHealthy → 서버 꺼짐
- Auto Sacaling 까지 연계해야 제대로 된 사용!
- 대체 인스턴스 추가
- 최소 / 최대 개수 설정
- 참고
- Manifest에 명시적으로 설정 필요
apiVersion: v1
kind: Pod # 이렇게 kind 설정이 중요, 종류에 따라 아래 동작 방식이 달라짐
metadata:
name: webapi
spec:
containers:
- name: webapi
image: maho/webapi:0.1
livenessProbe:
# (1) 핸들러를 구현한 애플리케이션
# (2) 애플리케이션이 살아있는지 확인
httpGet:
path: /healthz # 확인 경로
port: 3000
initialDelaySeconds: 3 # 프로브 시작 대기 시간
periodSeconds: 5 # 검사 간격
readinessProbe:
# (3) 애플리케이션이 준비되었는지 확인
httpGet:
path: /ready # 확인 경로
port: 3000
initialDelaySeconds: 15 # 프로브 검사 시작 전 대기 시간
periodSeconds: 6 # 검사 간격- 파드 내 초기화만을 수행하는 컨테이너와 요청 처리를 하는 컨테이너를 별도로 개발하여 재사용
- 스토리지를 마운트 할때 새로운 디렉터리를 만들어 소유자를 변경한 후 데이터를 저장 하는 초기화 처리
- initContainer 를 먼저 실행하여 공유 볼륨을 /mnt에 마운트 , /mnt/html 폴더를 추가 후 소유자를 변경
- 이후 메인 컨테이너가 기동되어 해당 공유 볼륨을 마운트하여 사용한다.
8-3. 사이드카 패턴 - Dockerfile
- 하나의 파드 안에 여러 개의 컨테이너를 담아서 동시에 실행하는 패턴
- 웹서버 컨테이너 + 최신 콘텐츠를 깃허브에서 다운받는 컨테이너 = 사이드카
- 즉, 메인 애플리케이션 컨테이너와 보조 기능을 수행하는 컨테이너를 함께 배포하는 패턴
사이드카 패턴 사용 이유
- 애플리케이션 변경 없이, 사이드카를 붙였다 떼거나 교체하기 쉬운 구성 방식이다.
주의할 점
- 메인과 사이드카 컨테이너가 같은 노드에서 실행되므로 리소스 설정이 중요하다.
- 두 컨테이너 간 의존성 관리가 필요하다.
- 사이드카 컨테이너는 메인 컨테이너 보다 나중에 시작/종료 해야 한다.
8-4. 애플리케이션 버전 변경 전략
1) 재생성 전략 (Recreate)
- 재배포!
- 디플로이먼트와 관련된 모든 포드를 중지 → 새로운 버전의 포드를 생성
- 장점 : 쉽고 간편하다
- 단점 : 서비스 다운타임이 발생한다.
- 서비스에 영향이 있다.
- 기능 테스트 배포에 적합하다.
2) 롤링 업데이트 전략 (Rolling Update)
- Blue / Green 배포 방식과 유사
- 기존 버전의 애플리케이션을 점진적으로 새로운 버전으로 교체하는 배포 방식
- 트래픽을 기존 버전(V1.1)과 새 버전(V1.2)으로 분산하면서 배포
- 사실 사용자 경험 측면에서는 서버가 내려갔다는 것도 못 느끼지만,
아주 희박한 환경에서의 에러가 난다면?- 기존 v1.1에 있던 사용자
- 로그아웃
- 심한 경우 500 에러
- [그런데 결제 중이었다면?]
- 실제 결제는 되었는데, 사용자는 v1.2로 옮겨가고 사이트에서는 재결제가 뜸
- → ALB에서 Connection Draining(연결 지연 종료) 기술
- 기존 V1.1에서 요청을 처리 중인 사용자가 있다면
해당 요청이 끝날 때까지 기다린다. - 모든 연결이 종료된 후, 완전히 전환
- 세션이 끊길 때 대기하는 것
- 기존 V1.1에서 요청을 처리 중인 사용자가 있다면
- 완벽한 해결일까?
- 기존 연결이 강제 종료되는 문제를 해결하지만, 세션 유지 문제는 해결하지 못함
- 1) 세션 기반 애플리케이션 (로그인, 결제 등)은 해결되지 않음
- Connection Draining은 진행 중인 요청만 유지해줄 뿐, 새 요청까지 보장하지 않음
- 세션이 메모리에 저장되어 있다면, 서버 교체 시 세션이 사라질 가능성 있음
- 결제 진행 중일 때 사용자가 새로운 버전(V1.2)으로 이동하면 세션이 끊기고 재로그인 요구
- 2) 웹소켓, 장기 연결(Long-lived connections)에 취약
- WebSocket 같은 경우, 클라이언트가 지속적으로 서버와 연결을 유지함
- Connection Draining이 끝난 후에는 새로운 서버(V1.2)로 강제 이동해야 함
- 3) 완전한 무중단 배포가 어려움
- 기존 요청을 마친 후 서버를 종료하더라도, 세션을 공유하지 않으면 로그인 유지가 불가능
- Sticky Session을 설정하면 해결 가능하지만, 서버가 교체되면 Sticky Session도 의미가 없음
- ⇒ 실무 : Connection Draining + 세션 공유(redis 등) + Canary 배포 활용
- 세션 공유
- 세션을 서버에 저장하면 배포 시 세션이 사라지므로, 반드시 중앙 저장소 사용 필요
- Redis, Memcached 같은 세션 스토리지
- 레디스락..?
- Canary 배포
- 일부 사용자(예: 1~5%)만 새 버전으로 전환 후 안정성이 확인되면 전체 배포
- 롤백 가능
- 단점 : 리소스를 두 배로 사용… 비용 증가
- 이중 트랜잭션 처리 → DB + 메시지 큐(Kafka, SQS)를 활용하여 트랜잭션 상태 유지
- Idempotency Key 적용 → 중복 요청을 방지하여 결제가 두 번 이루어지지 않도록 함
- 트랜잭션 스토리지 사용 (DynamoDB, Kafka, SQS 등)
- 세션 공유
- 기존 v1.1에 있던 사용자
- ⇒ 그냥 이런 기능있네? 좋다! 도입하자!
- 가 아닌 “서비스” 레이어의 WorkFlow를 생각하는 것이 아키텍쳐 / 기술 선택에서 중요하다.
9. 서비스
9-1. 서비스
서비스 필요의 이유
- Pod에도 고유 IP가 있기는 함!
- 하지만, Pod는 생성/삭제될 때마다 IP가 변경됨.
- → 서비스는 고정된 "대표 IP(Cluster IP)"를 제공하여 안정적인 접근을 가능하게 함.
- DNS 기반의 서비스 검색 기능을 지원하여, 서비스 이름을 통해 접근 가능
- 트래픽을 여러 Pod에 분산하는 로드밸런서 역할도 수행한다.
서비스의 동작 순서 (ClusterIP)
- 대표 IP를 통해 클라이언트 요청을 받음.
- Docker는 -p 8080:80 설정 후 직접 접근 가능
- K8s는 반드시 서비스를 통해 Pod까지 접근해야 함
- 내부 DNS에 서비스 이름을 등록하여 클라이언트가 서비스 이름으로 접근 가능.
- 셀렉터(Selector)를 사용하여 특정 라벨(Label)을 가진 파드로 트래픽을 전달.
- 서비스가 생성된 후 실행된 컨테이너는 자동으로 환경 변수를 설정하여 서비스 정보를 얻을 수 있음.
Cluster IP (대표 IP)
- Pod들의 그룹을 대표하여, 대표 IP(Cluster IP)를 가진다.
- Cluster IP : 내부에서 작동하는 IP
- 파드의 IP주소를 내부 DNS에 직접 설정한다.
환경 변수
- 서비스 만들어진 후 생성되는 파드의 컨테이너는 환경 변수가 설정됨
- → 이 환경 변수를 이용하여 서비스의 대표 IP를 얻을 수 있다.
9-2. 부하분산과 어피니티
부하분산
- 대표 IP 주소에 도착한 Request들은 라벨(Labels)과 셀렉터(Selectors)이 일치하는 파드를 찾아 전송하게 된다.
- 같은 라벨을 가진 파드가 여러 개라면, 부하분산은 Default로 랜덤임.
- 여러 Pod에 대한 로드밸런싱 풀을 구성하여, 부하를 분산
어피니티
- 요청받는 파드를 고정하고 싶은 경우
- session Affinity 항목에 Cluster IP를 설정
- HTTP 헤드 안의 쿠키 값에 따라 전송되는 파드의 고정을 원하는 경우 인그레스 이용
- 리버스 프록시 값에 따라 이동
10. 서비스 종류 ; 클러스터 네트워킹
- 쿠버네티스에는 4가지 대응해야 할 네트워킹 문제가 있다.
- 고도로 결합된 컨테이너 간의 통신: localhost 통신
- 파드 간 통신 : 이전에 다룬 ClusterIP로 해결
- 파드와 서비스 간 통신 : 서비스(ClusterIP, NodePort) 활용
- 외부와 서비스 간 통신 : NodePort, LoadBalancer, Ingress 사용
10-1. ClusterIP (Default) : 클러스터 내부 전용
- 내부의 다른 파드에서만 접근 가능
- 서비스 타입을 지정하지 않으면 → Cluster IP로 만들어진다.
[서비스 예시]
- spec.type 설정이 없으면 Default로 ClusterIP
apiVersion: v1
kind: Service
metadata:
name: myservice # Service 이름 (kubectl get svc myservice로 조회 가능)
# namespace: default # 네임스페이스에 생성 : 설정 없으면 'default'
labels:
hello: world # Service에 'hello: world' 라벨 부여
spec:
ports:
- port: 8080 # Service가 노출하는 포트 (ClusterIP 기준)
protocol: TCP
targetPort: 80 # 실제 Pod 내부에서 실행 중인 컨테이너의 포트 (nginx의 기본 포트 80)
selector:
run: mynginx # 이 Service가 라우팅할 Pod 선택 (라벨 'run=mynginx'인 Pod과 연결)
(1) Pod IP로 직접 요청 보내기
- Pod IP로 직접 요청을 보내는 것도 가능하다.
# mynginx Pod의 Ip 확인
kubectl get pod -owide
# client -> mynginx Pod의 Ip로 전송
kubectl exec client -- curl -s 10.244.0.85
# mynginx -> client Pod의 Ip로 전송
kubectl exec mynginx -- curl -s 10.244.0.85- 하지만, Pod는 생성/삭제될 때마다 IP가 변경되며, 서비스를 활용해 고정된 "Cluster IP"로 통신하는 것이 좋다고 했다.
(2) ClusterIP를 통해 요청 보내기
# 서비스 IP (Cluster IP) 확인
kubectl get svc
# Cluster IP로 요청 (myservice 서비스)
kubectl exec client -- curl -s <myservice Cluster IP>:8080
(3) Service Discovery : DNS를 통해 서비스 이름으로 요청 보내기]
# 서비스 이름 (DNS)로 요청
kubectl exec mynginx -- curl -s myservice:8080
10-2. NodePort : 클러스터 내부 + 외부
- Cluster IP의 기능에 더해진 것
- 공개 포트가 오픈된다. (30000~32767)
- 각 노드가 수령한 요청은 대상 파드들에 부하분산된다. (정식서비스에 사용하는 것은 비추천)
- 외부에서도 각 노드의 IP/ 특정 포트로 접근 가능
- 내부적으로도 각 Worker 노드간에 통신할 수 있다!
10-3. LoadBalancer : 클러스터 내부 + 외부 (대표 IP 제공)
- 로드밸런서[ALB, NLB]와 연동 → 외부에 공개
- 로드밸런서는 NodePort를 사용하기 때문에 Cluster IP도 자동할당 된다.
- 퍼블릭 클라우드 환경(AWS)에서 제공되는 로드밸런서와도 연동 가능
- → ALB로 들어온다.
10-4. ExternalName : 외부 서비스 연결
- 외부의 엔드포인트에 접속하기 위한 이름을 해결
- 퍼블릭 클라우드의 DB나 외부 API 서비스등을 접근할 때 사용
- 서비스의 이름과 외부 DNS 이름의 매핑을 내부 DNS에 설정
- 외부 엔드포인트에 접근 가능
- 포트까지 지정은 불가능
10-5. 서비스와 파드의 연결
- 서비스는 셀렉터(Selector)와 라벨(Label)을 이용해 특정 파드에 트래픽을 보냄.
- 서비스가 자동으로 환경 변수를 설정하여 컨테이너에서 쉽게 접근 가능.
- 부하 분산(Load Balancing) 기능이 기본 제공됨.
⇒ "ClusterIP"는 기본값이며, 외부 접근이 필요하면 "NodePort" 또는 "LoadBalancer"를 사용해야 한다.
11. 인그레스 (Ingress) : 외부와 서비스 간 통신
- Ingress는 쿠버네티스 클러스터 내부의 서비스(Service)와 외부 트래픽을 연결시켜준다.
- ⇒ 파드에서 실행 중인 애플리케이션을 클러스터 외부에서 접근 할 수 있다.
- 로드밸런싱, HTTPS 적용, 도메인 기반 호스팅 등 다양한 기능 제공
- 기존의 로드밸런서를 대체할 수 있다.
- → 하나의 엔드포인트를 통해 여러 서비스에 접근 가능
11-1. 공개 URL과 애플리케이션 매핑
- Ingress는 외부에서 들어오는 URL 요청을 내부 애플리케이션(서비스/파드)로 매핑하는 역할
- 도메인 기반 라우팅을 지원하며, 여러 애플리케이션을 하나의 Ingress 리소스에서 관리 가능
- Selector : Match Label
- 예시) Web : Oreder
- 각 파드들이 연결
kubernetes.io/ingress.class: "nginx"
- 클러스터 내에 여러 Ingress 컨트롤러(Nginx, Traefik 등)가 있을 경우, 특정 컨트롤러를 지정할 필요가 있음.
- 위 설정이 없으면 모든 Ingress 컨트롤러가 요청을 처리하려고 할 수 있음
nginx.ingress.kubernetes.io/rewrite-target: /URL
- 기본적으로 클라이언트의 요청 URL(/reservation, /order)을 그대로 전달
- 하지만 백엔드 서비스에서 /reservation 같은 경로가 필요 없을 경우, 이 설정을 사용해 URL을 /로 변경
- 예제에서 /reservation 요청이 들어와도 api-reservation-svc에서는 /로 인식하여 처리 가능
- 이 설정이 없으면 클라이언트 요청을 그대로 전송하여 FIle NotFound 에러가 발생한다.
ConfigMap을 이용한 Nginx 설정 적용 (미들웨어 설정)
- Nginx, Apache 같은 미들웨어 설정을 ConfigMap을 사용하여 동적으로 관리 가능
- ConfigMap을 마운트하면 파드가 파일 시스템처럼 설정 값을 읽을 수 있음
11-2. 모더니제이션과 세션 어피니티(Session Affinity)
- 웹 애플리케이션에서는 로드밸런서의 세션 어피니티가 일반적
- 브라우저는 무상태(Stateless) 프로토콜이므로 클라이언트-서버 간 세션 유지 불가
- 세션 정보를 기반으로 로드밸런서가 동일한 서버로 요청을 유지해야 함
- ⇒ 쿠버네티스의 세션 어피니티(Session Affinity)
세션 어피니티(Session Affinity) ; Client IP 기반
- 로드밸런서나 Kubernetes Service가 클라이언트의 IP를 기반으로 세션을 유지
- 클라이언트의 IP를 기반으로 특정 Pod에 지속적으로 연결하는 방식
- 로드밸런서가 같은 클라이언트의 요청을 항상 같은 서버(Pod)로 보내는 기능
- 쿠키가 필요 없고, TCP/UDP 같은 HTTP가 아닌 프로토콜에서도 사용 가능
- 🚨 단점 : 클라이언트의 IP가 변하면 다른 Pod로 연결될 수 있음 (모바일, VPN 등 IP 변동이 많은 환경 사용 시 문제 발생)
+ Sticky Session ; Cookie 기반
- 클라이언트 요청이 특정 Pod로 유지되도록 로드밸런서에서 쿠키를 발급하여 관리
- 일반적으로 HTTP 쿠키(Set-Cookie 헤더)를 활용하여 세션을 유지
- 클라이언트가 보낸 요청을 항상 같은 Pod로 보냄 (서버 메모리에 저장된 세션 유지 목적)
- NGINX Ingress 에서 MY_SESSION이라는 쿠키가 설정되면, 클라이언트는 항상 같은 Pod로 연결됨
- 🚨 단점 : 하지만, Pod가 삭제되면 쿠키 세션이 유지되지 않음 (이러한 경우, 외부 세션 저장소 필요)
11-3. HPA 설정
- Horizontal Pod Autoscaler
- 리소스 사용량(CPU, 메모리 등)에 따라 자동으로 Pod의 개수를 조정하는 기능
- Ingress와 HPA를 함께 사용하여 트래픽 증가 시 자동으로 Pod를 확장할 수 있다.
- 특정 Deployment 또는 ReplicaSet을 모니터링하며,
리소스 사용량이 기준을 초과하면 자동으로 Pod를 추가 / 감소하면 Pod를 감소
Deployment/ReplicaSet VS HPA ?
- Deployment/ReplicaSet
- "고정된 개수의 Pod"를 운영
- 수동으로 임의 값을 지정하여 pod에 대한 확장, 기존 컨테이너 유지 등의 기능을 제공
- (물론 Selfhealing등은 현재 컨테이너를 유지하기위해 자동으로 동작)
- HPA
- "동적으로 Pod 개수”를 조절
- HPA의 경우 Metric Server와 연계되어 CPU, MEM, Network 등의 메트릭 값을 이용하여 동적으로 컨테이너를 확장하는 개념
- HPA는 메트릭값에 의해 동적으로 조작
12. 로드밸런싱
Flannel
- 간단한 L3 네트워크
Calico
- 접근 제어 기능 추가 제공
- Master - worker
- worker - → Calico 설정 안하면, 노드간 통신 불가능
- 모든 네트워크 설정이 끝나면 꼭 Calico 설정이 필요하다.
13. 스토리지
13-1. 스토리지
Docker Volume과 비슷한 개념
- 대표적으로 Log 저장
- 외부 스터리지를 사용하고자 할 때
- 전용 스토리지 + 서버 클러스터링 두 가지를 조합한 방법
- 외부 스토리지의 논리적인 볼륨을 Pod 내부에 마운트하는 것을 의미한다.
13-2. 스토리지 사용 방식 비교
| 스토리지 방식 | 설명 |
예시 |
|---|---|---|
| 전용 스토리지 (Dedicated Storage) | 특정 스토리지에 직접 연결하여 사용 | AWS EBS, NFS, Ceph |
| SDS (Software-Defined Storage) | 여러 서버를 클러스터링하여 저장 공간을 공유 | GlusterFS, Ceph, Longhorn |
| 하이브리드 (Dedicated + SDS) | 전용 스토리지와 SDS를 조합하여 고가용성 제공 | Ceph + EBS 조합 |
- EBS (gp2, gp3)
- 인스턴스 생성 설정할 때 AWS에서의 스토리지 구성 화면
- 외부 스토리지 시스템의 API 사용하여 볼륨을 자동으로 준비해 주는 방법 (동적)
- 외부 스토리지 시스템의 설정을 직접 진행하는 방법 (수동)
- “Demon Set을 이용해서 S3에 적재하는 방식”도 있다.
- PV/PVC는 Kubernetes에서 관리하는 "마운트된 스토리지"를 의미
- 이 방식은 직접 S3 같은 오브젝트 스토리지에 데이터를 저장하는 접근법
<오브젝트 스토리지(S3)> - 실무에서 자주 사용
반응형