
Computer Science/분산시스템
Chapter 7. Consistency and Replication
dog-pawwer
2024. 1. 2. 14:01
반응형
1. Replication
복제 : 여러 개의 copy 본을 만들어서 사용한다.
- data replcation : 같은 data를 다른 device로
- ex. browser cache, DNS (캐싱 혹은 DNS)
- computation replication : 같은 연산을 여러 번 수행
- replcated in space : 서로 다른 장치에서 같은 연산
- replcated in time : 한 장치에서 반복
2. 왜 ‘복제’하는가?
- 신뢰도
- 만약에 하나의 레플리카가 사용 불가능한 경우, 다른 복제본을 사용 → 보험용
- 손상된 data → isolation 시키고, replica로 실행한다. → 손상된 데이터에 대한 보호
- 성능
- 분산 시스템의 크기가 커짐에 따라 확장
- 지리적으로 분산된 시스템에서의 확장 ( WEB proxy ) → latency 🔻
- 고려해야할 점
- replcated date 들끼리의 maintain consistency
3. Object Replication ; 동일한 데이터나 객체를 여러 위치에 복제하는 것
// 분류 기준 : 데이터의 복제와 일관성 유지에 대한 책임을 어디에 두는지
- 방식 1: 응용 프로그램이 복제를 담당!
- 응용 프로그램이 데이터의 복제를 직접 담당 → 복제의 책임이 응용 프로그램에게 있다.
- 일관성 문제를 응용 프로그램이 직접 처리!
- 방식 2: 시스템(미들웨어)이 복제를 처리!
- 응용 프로그램은 단순히 미들웨어에 데이터만 전달.
- 일관성 문제를 미들웨어에서 처리!
- 응용 프로그램 개발을 단순화하지만, 객체별 솔루션을 어렵게 만든다.
- ⇒ 특정 object에 대한 솔루션을 구현하기 어렵다.
→ 방식 1 : 응용 프로그램이 직접 관리하므로 세밀한 제어가 가능하지만,
방식 2 : 미들웨어가 이를 처리하므로, 응용 프로그램은 간단! but, 특정 객체에 대한 solution을 구현하기가 더 어려워질 수 있다.
4. 복제와 확장
- system Scalability 를 위해 Replication 과 Caching 활용
- Read를 많이 하는 system에서 replication의 장점 활용하기 좋은 이유 :
- access latency 🔻 → 성능을 향상
- but, 일관성을 유지하기 위해 network overhead 🔺
- 예시: 객체가 N 번 복제됨
- 읽기 빈도 R, 쓰기 빈도 W 라고 하자
- R<<W 인 경우, (읽기보다 쓰기를 압도적으로 많이 하는 경우)
- → 내용 변경 정도 多 → 높은 일관성 오버헤드와 낭비된 메시지 발생!
- 백날 일관성 유지 하다가 오히려 손해.
- // Read 빈도가 많으면 일관성 유지에 대한 overhead가 거의 없다. (Ex. OTT, Youtube … )
- 엄격한 일관성 (Tight Consistency)
: 모든 복제된 데이터의 모든 복사본은 항상 일관성을 유지해야 함.- 업데이트는 single atomic operation으로 수행됨.
(모든 replica 갱신까지의 연산 1회. atomic ; 쪼갤 수 없는 최소 단위 )
(ex. DB에서의 transaction ) - 대규모 네트워크에서 scalability problems 발생.
- 모든 복제본을 일관성 있게 유지하기 위해 전역 동기화 필요.
- 높은 수행 능력을 요구한다!!
- 업데이트는 single atomic operation으로 수행됨.
- 해결책: loosen consistency requiremnets (일관성의 기준 완화!!)
→ 엄격한 일관성은 데이터의 높은 일관성을 제공하지만, 이는 대규모 시스템에서의 성능 문제를 야기할 수 있다.
일관성을 완화하면서도 시스템이 원하는 수준의 성능을 유지하도록 다양한 일관성 모델을 선택하는 것이 중요!
5. 데이터 중심 일관성 모델 (Data-Centric Consistency Models)
- 일관성 모델
(Consistency model) = (consistency semantics)- 프로세스와 데이터 저장소 간의 계약 ( ex. 데이터의 읽기 및 쓰기 동작에 대한 규칙 )
- 프로세스가 특정 규칙을 따른다면, 데이터 저장소는 올바르게 작동할 것이다!
- “Read the last write!”
- 공유 데이터 항목 X에 대한 모든 읽기는 X에 대한 가장 최근의 쓰기 작업에서 저장된 값을 반환함.
- 전역 시계가 없으면 어떤 쓰기가 정확히 마지막인지 몰?루.. ❓
- 따라서 이를 위해 “정의”가 필요함. [일관성의 정도 / 범위]
들어가기 전
- Strict Consistency → Seqeuntial Consistency → Causal Consistency 순으로 점점 loose 해진다.
- ex)
- “ P1 : W(x)a “ : 프로세스 P1이 공유 데이터 x에 대해 a라는 값을 쓰기(Write) 작업 수행함.
- “ P3 : R(x)b “ : 프로세스 P3가 공유 데이터 x에 대해 읽기(Read) 작업을 수행하여 b라는 값을 얻음.
a. Strict Consistency
- 가장 엄격한 일관성 !
- 공유 데이터 항목 X에 대한 읽기 = “ X에 대한 가장 최근의 쓰기 작업에 의해 저장된 값 → 반환 “
두 프로세스가 동일한 데이터 항목 x 에 대한 작업의 동작.
a) 엄격한 일관성을 가진 저장소.
b) 엄격한 일관성을 가지지 않은 저장소.

- 모든 데이터 항목이 NIL로 초기화되었다고 가정.
- W(x)a: x에 값 a를 쓰기
- R(x)a: x를 읽으면 값 a를 반환그러나 이러한 접근 방식은 분산 환경에서 실현 가능성 X
- → 어떤 프로세스가 데이터를 쓰면, 그 데이터를 읽는 다른 프로세스는 항상 해당 가장 최근의 값을 볼 수 있어야 한다.
⇒ 분산 환경에서는 global clock이 없이, "가장 최근"에 대해 정의하기 어려움.
b. Sequential Consistency
- 모든 실행의 결과는 동일: 어떤 실행이든, 그 결과는 동일하다.
- 모든 프로세스의 작업을 일렬로 배열 가능: 모든 프로세스의 작업이 어떤 순차적인 순서로 실행된 것과 동일한 결과를 얻을 수 있다.
- 해당 쓰기의 순서는 scheduling이 정해주는 것이므로, 어떤 순서든 가능함. P1이 먼저 쓰든, P2가 먼저 쓰든.
- P2가 쓴 작업 (b값)을 읽는 행위가 먼저 실행됨.
- ⚠️b읽고 a 읽으세요! (P2→P1) 순서가 결정.
- 이 결정은 이후 읽는 모든 process들은 바뀌지 않음
- (b) 와 같이 순서가 바뀌면 sequntialluy 하지 못한 consistent이다.
- P1과 P2에서의 쓰기는 서로 어떤 순서로든 스케줄될 수 있지만,
- 한 번 순서가 결정되면 P3와 P4는 그 작업들을 동일한 순서로 볼 수 있어야 한다.
- 다시 말해, 한 프로세스에서 수행된 작업들은 해당 프로세스의 프로그램에 명시된 순서대로,
다른 프로세스에서는 그 순서와 일관성을 유지하여 볼 수 있어야 합니다.
→ 여러 프로세스 간의 작업을 일렬로 배열함으로써, 결과적으로 일관성을 유지하면서도 동시에 여러 작업을 수행할 수 있게 된다.
c. Causal Consistency
; Cause(원인)
- Weakening of sequential consistency ; 위의 일관성 모델을 조금 더 유연하게 풀어줌.
- 인과 관계(Causally related)가 있는 쓰기는 모든 프로세스에게 동일한 순서로 표시되어야 함.
(= happens-before)- 동시적인 쓰기(concurrent)는 다른 기계에서 다른 순서로 볼 수 있음.
- 허용되지 않음: 두 쓰기 W(x)a와 W(x)b는 인과 관계가 있음. (전후 관계) → 순서 변경은 금지 ❌
- 허용됨: 두 쓰기 작업 W(x)a와 W(x)b는 동시에 발생한 것으로 간주됨. → P에 따라 작업 순서를 다르게 인식할 수 있음.
- 전후관계(Causally related)가 있는지 check
- 다른 process에서 W(x)a→R(x)a 하면 전후관계 성립
- 한 process에서 연속으로 일어난 작업.
6. Caching
a. WWW에서의 캐싱
- caching도 replication의 일종이다.
- web access는 uniform(균등) 하지 않음 → 하나의 서버, load & latency 🔺
- 해결책 : 웹 프록시 캐시 사용
- server와 client가 지리적으로 멀 때! proxy를 통해 통신!
- → 사용자 응답 시간, 서버 부하, 네트워크 부하 감소
b. WEB 캐싱
- 웹 캐싱 및 복제 문제를 설명하기 위한 웹의 예제
- 더 간단한 모델: client는 읽기 전용! server만 데이터를 업데이트!
- cache된 것이 있다면, proxy가 대신 가져옴!
7. 일관성 문제
- 웹 페이지는 시간이 지남에 따라 업데이트됨
- 일부 객체는 정적이고, 일부는 동적!
- 다양한 업데이트 빈도 (몇 분부터 몇 주까지) = 업데이트 빈도를 다르게 설정
- 프록시 캐시가 캐시된 데이터의 일관성을 어떻게 유지할 수 있을까?
- 무효화 또는 업데이트 전송
- 푸시 대 풀
a. Push-based approach
- 서버는 객체를 요청한 모든 (cache가 있는) 프록시를 추적!
- web page 업데이트! → 모든 proxy에게 notify!
- notify 유형
- invalidate : 객체가 변경되었음을 나타냄
- update : 객체의 새 버전을 전송
- notify 유형
- 어떻게 무효화와 업데이트를 결정하는가?
- ex) 자주 변하는 object는 update, 나머지는 invalidate !
- 장점
- tight한 일관성! ⇒ [오래된 data를 최소화!]
- server가 push! ⇒ 프록시는 수동적
- 단점
- 서버에서 상태를 유지해야 함
- 가장 흔히 쓰이는 HTTP는 stateless!! 하잖아…
- → HTTP 이상의 메커니즘이 필요해…
- 서버와 proxy가 지속적인 통신 필요
- NOT RESILIENT (신축성 / 회복성) to server crashes
- 서버 충돌에 강하지 않음
(server가 고장나면, state를 유지하기 힘들다)
- 서버에서 상태를 유지해야 함
b. Pull-based Approach
(주기적으로 물어봐! HTTP 기반에 더욱 적합!)
- Proxy가 일관성을 유지하는 데 전적인 책임을 지게 된다!!
- Proxy는 정기적으로 서버에 polling하여 객체가 변경되었는지 확인!
- if-modified-since HTTP 요청 헤더 사용
- ❓중요한 질문: 프록시는 언제 polling 해야 할까? (얼마나 자주!?)
- 서버에서 할당한 Time-to-Live (TTL) 값 마다!
- 단점 : 객체가 TTL 주기 사이에 변경될 경우, 일관성 보장 못해줌…ㅠㅠ
- 서버에서 할당한 Time-to-Live (TTL) 값 마다!
⇒ proxy가 Web server에게 주기적으로 (TTL 값마다) polling 보냄! (바뀌었는지 물어봄!!)
c. Pull-based Apporach : Intelligent ver
- 프록시는 refresh interval(새로 고침 간격)을 동적으로 결정할 수 있음!
- HOW? : 과거의 data를 사용하여 미래 예측
- 보수적인 새로 고침 간격으로 시작
- 두 연속적인 폴링 사이에 객체가 변경되지 않았으면 간격을 증가
- 두 폴링 사이에 객체가 업데이트되었으면 간격을 감소
- 적응형 : 객체 특성에 대한 사전 지식이 필요하지 않다! = intelligent 하다!
⇒ 자주 바뀌면 : Poll 주기 🔻 / 덜 바뀌면 : Poll 주기 🔺
- 장점
- HTTP를 사용해 구현 가능하다! (If-modified-since)
- 서버는 상태를 유지하지 않아도 됨.
- 서버는 프록시와의 통신에서 발생하는 모든 정보를 지속적으로 추적할 필요 ❌
- 서버 및 프록시 장애에 강하다!
- 단점
- 일관성 보장이 상대적으로 약함 ㅠㅠ
- 두 polling 간에 객체가 변경될 수 있고, 프록시는 다음 polling까지 구식 데이터를 포함하게 된다.
< 강한 일관성을 원한다면 모든 HTTP 응답 전에 폴링해야만 한다. >
- 두 polling 간에 객체가 변경될 수 있고, 프록시는 다음 polling까지 구식 데이터를 포함하게 된다.
- 더 복잡한 프록시가 필요함
- 주기적인 polling으로 인한 높은 메시지 오버헤드
- 일관성 보장이 상대적으로 약함 ㅠㅠ
d. A Hybrid Approach: Leases (임대 방법)
( Push & Poll 두 가지 방법을 합침 !! )
- Lease (임대): 서버가 프록시에게 수정 사항을 알려야 하는 기간
→ 서버는 이 기간 동안 프록시에게 변경 사항을 통지할 것을 약속하게 됨! - 첫 Request에 대한 Lease 발급, 만료될 때까지 알림 전송 (만료 시 임대 갱신 필요)
- Zero duration => polling, Infinite leases => server-push
- lease의 지속 기간이 0 (lease가 발급되더라도 즉시 만료됨)
⇒ 프록시는 매번 서버에게 객체의 변경 여부를 확인하기 위해 주기적으로 polling을 수행. - lease의 지속 기간이 무한 (리스가 만료되지 않음)
⇒ 프록시는 서버로부터 변경 사항이 있을 때마다 즉시 notify을 받을 수 있다. push!!
- lease의 지속 기간이 0 (lease가 발급되더라도 즉시 만료됨)
- 효율성은 lease duration에 따라 달라진다.
Leases Duration에 대한 정책
- Age-based Lease (나이 기반):
- 개체 수명의 짧다 or 길다 이중적으로 바라봄.
- 예상 수명이 길다고 예상되면 더 긴 lease!
- Renewal-frequency based (인기순):
- 불균형한 인기!
- 인기 있는 프록시가 더 긴 lease!
- Server Load-based (Heavy순):
- 서버 부하가 높을 때 더 짧은 lease!
- → 서버 부하가 높은 놈, state space을 적게 사용하고자.
8. 협력적인 캐싱 모델 (EX. CDN)
- Caching 인프라는 여러 web proxy들을 가질 수 있다!
- 프록시는 계층 구조 (또는 다른 구조)로 배열될 수 있다.
- Overlay network of proxies: CDN (콘텐츠 전송 네트워크)
- 프록시는 계층 구조 (또는 다른 구조)로 배열될 수 있다.
- 프록시는 서로 협력할 수 있다!
- 협력하여 클라이언트 요청에 응답!
- 협력하여 server notify를 전파할 수 있습니다.
a. Content Delivery Network(CDN) ; 콘텐츠 전송 네트워크
- 왼쪽 그림과 같이 여러 프록시들은 서버와 클라이언트 간의 중개자로 동작
- “가장 가까운” 프록시에서 클라이언트 요청을 처리
(ex. 아래의 end-host의 경우 바로 왼쪽의 proxy가 처리!! )
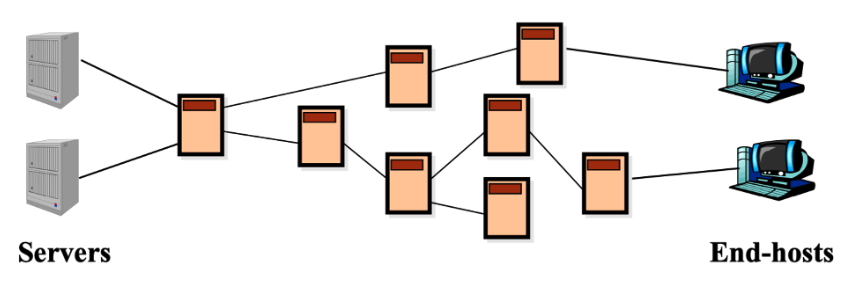
- CDN에서의 캐싱은 클라이언트 요청에 대한 응답을 "가장 가까운" 프록시에서 제공하기 위해 필요!
- ⚠️주의사항 : 여러 프록시 간의 캐시 일관성 유지가 필요!
- 왜 CDN인가?
(대규모 비디오 스트리밍 등에 사용)
- 도전 과제: 어떻게 선택된 콘텐츠를 수십만 명의 동시 사용자에게 스트리밍할 거야…??
메가 서버 하나 쓸 때의 문제점 & CDN을 사용하면 이점! - 옵션 1: 단일 대규모 Mega-server (전통적인 방법)
- SPoF (Single point of failure)의 문제 !!
- network congestion 문제
- 먼 클라이언트까지의 긴 경로
- 동일한 비디오 여러 복사본…
- ⇒ Scaliability 🔻
- 옵션 2: CDN 활용! // 2가지 방식
- Enter Deep!
- 사용자에 가까운 곳에 CDN 서버 배치! (Akamai 사용)
****→ 빠르고 안정적!
- 사용자에 가까운 곳에 CDN 서버 배치! (Akamai 사용)
- Bring Home!
- 더 큰 규모의 cluster를 POPs(접근지점) 근처에 배치! (Limelight 사용)
→ 성능 최적화!
- 더 큰 규모의 cluster를 POPs(접근지점) 근처에 배치! (Limelight 사용)
- Enter Deep!
- CDN 의 노드 선택 전략
- 도전 과제: CDN DNS는 클라이언트에게 스트리밍할 **좋은 CDN 노드를 어떻게 선택할까?
- 지리적으로 가장 가까운 클라이언트의 CDN 노드 pick!
- 클라이언트와의 delay 시간(or min # hop)이 가장 짧은 CDN 노드 pick!
- 대안: 여러 CDN 서버 목록 제공 → 클라이언트에게 결정 권한 부여
- “client, 너가 “best”한 node pick해!”
- Akamai CDN
CDN 기술의 선두주자.
- 전체 인터넷 트래픽의 15-20%를 처리
- 자체 DNS 서비스 운영
- 하루에 수천억 건 이상의 인터넷 상호 작용
Case 1: Netflix
- 2013년 기준 미국 하향 트래픽의 30% 차지
- 자체 인프라 소유량은 적음, 3rd party(제 3자) 서비스 활용
- Amazon (3rd 파티) 클라우드 서비스 사용
- 세 가지 3rd party CDN 사용 → Netflix 콘텐츠 저장, 호스팅, 스트리밍
- Akamai, Limelight, Level-3
- 2012년부터 자체 CDN 개발
Case 2: DASH
(Dynamic Adaptive Streaming over HTTP)
- DASH: HTTP를 통한 동적 적응 스트리밍
- 서버:
- 비디오 파일을 여러 chunk(작은 조각)로 나눔.
- 각 chunk는 다른 비율로 저장되고 인코딩
- 매니페스트 파일: 다른 chunk의 URL을 제공합니다.
- 클라이언트:
- 주기적으로 서버에서 클라이언트로의 bandwidth을 측정합니다.
- 매니페스트를 참고하여 한 번에 하나의 chuck 요청
- 클라이언트에서의 Intelligence : 클라이언트의 결정
- When : chunk를 언제 요청할지 (버퍼 기아 또는 오버플로우가 발생하지 않도록)
- What encoding rate : 요청할 코딩 비율을 결정. (대역폭이 더 많이 사용 가능한 경우, 더 높은 품질 선택)
- When : 어디에서 chunk를 요청할지 (클라이언트에 가까운 서버에서? or 고대역폭 서버에서?)
Case1+: Netflix의 대역폭 변화에 따른 user의 적응
- 질문: 클라이언트는 대역폭 변화에 어떻게 적응할까?
(네트워크 경로의 혼잡 수준 변화로 인해 대역폭이 변할 수 있다.) - 두 가지 클라이언트 기반 대안:
- 새 CDN 서버에서 비디오 가져오기? (new path!)
- DASH를 통해 비디오 스트리밍 속도 변경?
- 실험:
- 서버에서 클라이언트로의 대역폭을 체계적으로 감소시킴
- 클라이언트의 응답을 측정: 속도 감소 또는 서버 변경 → 2가지 중에서 선택.
반응형